AI IQ lança rankings em escala de QI para modelos de IA de fronteira, diz Ryan Shea no X
Plataforma consolida 12 benchmarks em uma escala de QI humano para comparar modelos de fronteira, adiciona EQ e custo efetivo, e já provoca debate entre pesquisadores e profissionais
Danilo Gato
Autor
Introdução
AI IQ está no ar com um objetivo direto, colocar modelos de IA de fronteira em uma escala de QI humano e mostrar quem está no topo, quanto custam por tarefa e como evoluíram no tempo. A plataforma, criada por Ryan Shea, usa o termo AI IQ como palavra-chave central e organiza um mercado confuso em gráficos que cabem em uma tela. O anúncio foi feito em 12 de maio de 2026 e rapidamente ganhou repercussão entre profissionais e pesquisadores.
Em vez de mais uma tabela de benchmarks, AI IQ agrega 12 avaliações públicas em quatro dimensões de raciocínio e entrega um QI estimado por modelo, além de um EQ estimado e um eixo de custo efetivo por tarefa. A proposta facilita decisões práticas para quem precisa escolher modelos por qualidade, custo e adequação. Ainda assim, reduzir capacidades a um único número exige cuidado na interpretação.
Como o AI IQ mede inteligência em escala de QI
O núcleo do AI IQ é simples de entender e rigoroso na coleta. Primeiro, a plataforma arquiva capturas de origem de leaderboards públicos e extrai somente valores com fonte verificável. Depois, mapeia cada nota bruta de benchmark para um QI implícito usando curvas de dificuldade calibradas. As 12 provas são agrupadas em quatro dimensões, raciocínio abstrato, matemático, programático e acadêmico. O QI final é a média das quatro dimensões, com imputações conservadoras quando falta cobertura, sem permitir que lacunas elevem artificialmente o composto.
A lista de benchmarks inclui conjuntos que estressam raciocínio fora do treino e tarefas técnicas difíceis, como ARC AGI 1 e ARC AGI 2, FrontierMath em seus tiers, AIME, ProofBench, Terminal Bench 2.0, SWE Bench Verified, SciCode, Humanity’s Last Exam, CritPt e GPQA Diamond. Essa seleção tenta equilibrar o problema clássico de saturação, quando muitos modelos topo de linha encostam no teto de uma prova e deixam de se diferenciar. O AI IQ lida com isso comprimindo tetos nas provas mais fáceis ou suscetíveis a contaminação de dados, preservando espaço de discriminação onde ainda há margem.
Na prática, esse desenho reconhece um fato do nosso momento, alguns benchmarks de raciocínio já foram “quebrados” por modelos recentes, enquanto outros ainda expõem limites claros. É exatamente por isso que iniciativas paralelas como ARC AGI 2 cresceram em importância, buscando medir inteligência fluida com problemas genuinamente novos.
EQ e o debate sobre inteligência emocional de modelos
AI IQ adiciona um segundo eixo, o EQ estimado. Ele é calculado a partir de dois sinais, EQ Bench 3, que usa julgamentos automatizados, e Arena Elo, que reflete preferências humanas em confrontos diretos entre respostas. Cada Elo é mapeado para um EQ em uma escala calibrada e o composto final é 50 por cento de cada, ou usa um único sinal quando só um está disponível. Como o EQ Bench 3 é julgado por um modelo da Anthropic, a plataforma aplica uma penalização de 200 pontos no Elo do EQ Bench para corrigir possível viés de família nesses casos, antes de converter para EQ.
Esse cuidado metodológico evita favorecer indevidamente uma família de modelos por conta do julgador, mas não encerra o debate. O ganho para quem constrói produtos é claro, cruzar QI e EQ no mesmo plano ajuda a escolher modelos para interfaces sensíveis a tom, empatia e colaboração, onde preferências humanas importam mais que acertar uma prova de olimpíada. A cobertura inicial da imprensa destacou exatamente essa diferença entre medir raciocínio puro e medir experiência conversacional percebida por pessoas.
Custo efetivo, o elo que faltava entre laboratório e produção
Além do QI e do EQ, a plataforma traz um gráfico de QI versus custo efetivo. O custo no eixo X é definido como o custo de tokens para um trabalho com 2 milhões de tokens de entrada e 1 milhão de saída, multiplicado por um fator de uso que captura a eficiência do modelo no consumo de tokens para completar a mesma tarefa. O resultado é um comparativo que espelha a realidade de quem olha fatura de API, modelos mais fortes também podem ser mais caros por tarefa, e muitos modelos de meio de pelotão entregam QI suficiente com custo muito menor.
Na leitura prática, esse gráfico incentiva estratégias de roteamento, usar modelos topo somente onde a diferença de QI muda o resultado de negócio, e escalar o meio de pelotão no grosso das tarefas. Isso já é padrão em times maduros de IA aplicada, mas ter uma régua visual, com curvas de indiferença configuráveis entre qualidade e custo, acelera decisões e alinhamento entre engenharia e produto.
O que os rankings mostram hoje
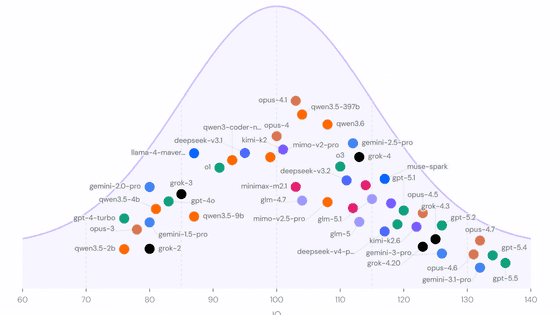
No momento do lançamento, os gráficos do AI IQ posicionam mais de 50 modelos na curva de QI, com uma concentração densa no topo. A cobertura inicial destacou que a diferença entre os líderes é pequena e que OpenAI, Anthropic e Google ocupam o andar de cima com variações mínimas, enquanto outras casas avançam rápido na faixa de custo desempenho. Uma captura do site mostra, por exemplo, a decomposição de um modelo de topo com QI agregado na casa de 136, junto do detalhamento por dimensão.
![Distribuição dos modelos por QI na curva normal, captura do AI IQ]
Outro gráfico agrega a trajetória temporal, conectando cada grande lançamento por provedor. A leitura é útil para separar hype de progresso real, quando um suposto sucessor não avança sobre o antecessor, o degrau fica visível. O recorte de outubro de 2023 até meados de 2026 evidencia um ganho acelerado e contínuo de QI estimado, com saltos associados a gerações que dominaram benchmarks mais duros.
![Evolução do QI de fronteira ao longo do tempo, por provedor]

Onde o AI IQ acerta e onde exige cautela
Acerta ao resolver três dores reais. Primeiro, consolida fontes públicas e permite comparação apples to apples sem garimpar posts de marketing e PDFs de pesquisa. Segundo, corrige saturação ao comprimir tetos em provas fáceis e priorizar benchmarks duros, reduzindo a chance de “otimização para a prova” distorcer o composto. Terceiro, incorpora custo e EQ, dois eixos decisivos para produto e atendimento. A documentação do próprio site explica como cada peça entra no cálculo e como as dimensões explicam o QI composto.
Exige cautela por quatro motivos. Um número só mascara a famosa irregularidade de capacidades dos modelos, o fenômeno de jaggedness, em que o modelo acerta álgebra avançada e falha em tarefas simples fora de distribuição. A crítica apareceu cedo nas redes, com alertas sobre a tentação de tratar o QI como território e não como mapa. Segundo, calibrações manuais introduzem julgamentos e pedem transparência continuada para manter a confiança da comunidade. Terceiro, os próprios benchmarks se movem, novas versões e suítes mais difíceis mudam o placar. Quarto, o QI humano é uma metáfora útil, não uma equivalência literal, por isso a leitura deve ser operacional, não antropomórfica. A cobertura jornalística reuniu esses pontos e reconheceu que, mesmo com limitações, o framework ajuda mais do que atrapalha quando usado com critério.
Aplicações imediatas para times de produto, dados e engenharia
- Seleção de modelo por caso de uso. QI alto tende a correlacionar com tarefas de raciocínio estruturado, como pesquisa, análise técnica e código, enquanto EQ forte favorece atendimento, ensino e co-criação com usuários. O gráfico IQ vs EQ ajuda a escolher a ferramenta certa para o trabalho, lembrando que curadoria e testes internos continuam mandatórios.
- Planejamento de custo, roteamento e SLOs. O diagrama QI versus custo efetivo, somado às curvas de indiferença entre qualidade e preço, suporta arquiteturas multi modelo com regras de roteamento por criticidade, orçamento e metas de latência. Em picos de volume, mover requisições para um modelo de QI médio pode preservar margem sem degradar resultado perceptível.
- Compras e governança. Consolidar em uma régua única reduz atrito entre áreas técnicas e executivas. A partir dos gráficos, fica mais simples justificar contratos, renegociações e pilotos controlados com novos provedores que aparecem bem posicionados na faixa de custo desempenho.
Como ler os gráficos sem cair em armadilhas
- Trate QI estimado como um índice composto de benchmarks, não como uma medida ontológica de “inteligência”. Modelos são ferramentas especializadas. Use o QI para shortlist e valide com seus dados e métricas de negócio.
- Observe a decomposição por dimensão. Dois modelos com o mesmo QI podem ter perfis inversos, um mais forte em matemática e fraco em acadêmico, outro ao contrário. A decisão certa depende do mix de tarefas que você precisa resolver.
- Compare custo efetivo nas situações que importam para você. O fator de uso em tokens varia de acordo com prompt, contexto e estilo de solução. Use o gráfico como guia e meça localmente com seus workloads.
- Releia a evolução temporal por provedor ao avaliar anúncios. Quando um lançamento não supera o degrau anterior, isso aparece visualmente e evita decisões baseadas apenas em narrativa de marketing.
O que isso diz sobre a próxima safra de benchmarks
Quando o topo converge e os testes ficam fáceis para os melhores, surgem novas suítes e revisões para restaurar a capacidade de discriminar. Essa dança é conhecida na literatura e já levou organizações a redesenhar índices inteiros quando saturaram. O AI IQ incorpora essa realidade ao comprimir os tetos onde julga necessário e ao priorizar benchmarks mais duros. A tendência é que o mix continue mudando, principalmente em direção a avaliações multimodais, agentes com ferramentas e tarefas de longo horizonte.
Ao mesmo tempo, vale lembrar o propósito original de provas como ARC AGI, medir inteligência fluida em problemas novos, minimizando memorização. Esses testes permanecem importantes porque modelam a capacidade de extrapolar, não apenas reproduzir padrões. Espera-se ver mais peso relativo nesses e em sucessores à medida que as provas antigas perdem poder de separação.
O debate público e por que ele é saudável
A recepção dividida é um bom sinal. De um lado, profissionais celebram a clareza de um painel que coloca QI, EQ e custo no mesmo mapa. Do outro, pesquisadores lembram que um número único convida à complacência analítica. A reportagem da VentureBeat reuniu exemplos dos dois lados e destacou que o próprio site documenta suas escolhas, como o ajuste de viés no EQ e as curvas de calibração no QI, mesmo que não publique todas as transformações como dados reproduzíveis. Essa tensão empurra a metodologia a evoluir, a abrir mais dados e a incorporar novos sinais.
No fim, a utilidade do AI IQ depende de como ele é usado. Como bússola para navegação rápida em um oceano de modelos, funciona muito bem. Como sentença definitiva sobre qual IA é “mais inteligente”, seria um atalho perigoso. O equilíbrio está em deixar que a régua compacte o espaço de busca e que testes internos, métricas de produto e ética de implantação decidam o resto.
Conclusão
AI IQ entrega uma régua prática para comparar modelos de IA de fronteira em uma linguagem que executivos e engenheiros entendem, QI estimado, EQ estimado e custo por tarefa. A plataforma consolida 12 benchmarks, corrige saturação onde precisa e adiciona visualizações que contam uma história clara do mercado. Usada como bússola, acelera decisões e aponta oportunidades de custo desempenho.
O cuidado é manter a humildade metodológica. Inteligência de modelos é irregular por natureza e nenhuma escala única capta toda a variação que importa. Os gráficos do AI IQ valem como convite à investigação, não como veredito. À medida que novos benchmarks surgem e o campo avança, essa régua pode continuar útil se acompanhar a mudança, documentar escolhas e permanecer aberta ao escrutínio público.