Arcee AI lança Trinity-Large-Thinking, raciocínio aberto Apache2.0
Trinity-Large-Thinking chega com pesos abertos sob Apache 2.0, foco em agentes de longo prazo e uso intensivo de ferramentas, prometendo preço por milhão de tokens agressivo e desempenho competitivo em benchmarks de agentes.
Danilo Gato
Autor
Introdução
Trinity-Large-Thinking é o novo modelo de raciocínio aberto da Arcee AI, lançado em 1 de abril de 2026 com pesos sob a licença Apache 2.0 e disponibilidade imediata via API e Hugging Face. Palavra-chave: Trinity-Large-Thinking. A empresa posiciona o modelo para agentes complexos, com chamadas de ferramentas em várias etapas e maior coerência em contextos longos.
O anúncio reforça a estratégia de abertura da Arcee AI, que já vinha preparando o terreno com o Trinity-Large-Preview em janeiro. Agora, o passo é explícito, a variante Thinking adiciona raciocínio estruturado antes de responder, o que melhora uso de ferramentas, aderência a instruções e estabilidade em loops de agente de longa duração.
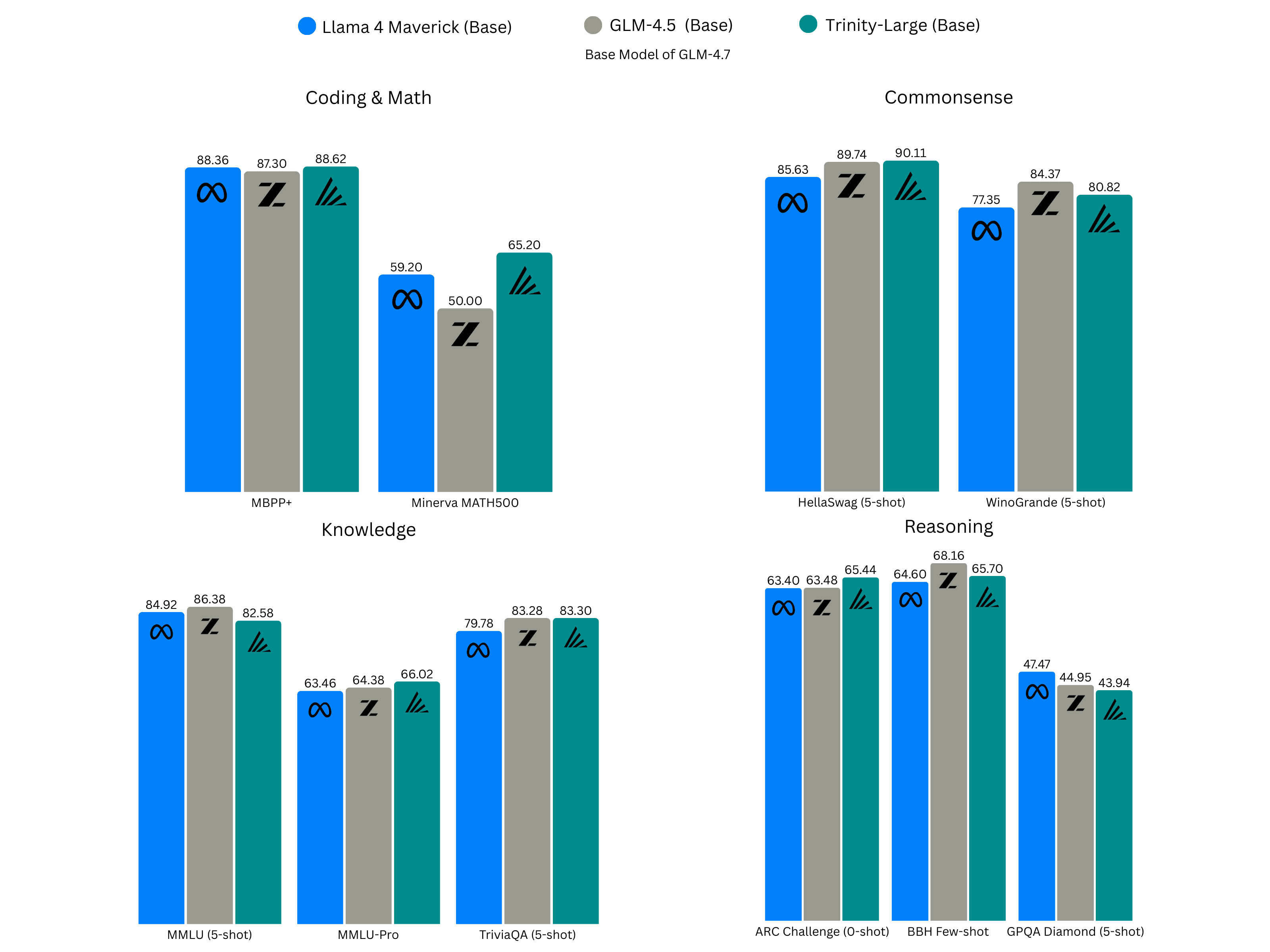
O que torna o lançamento relevante é a combinação de três fatores, abertura real com pesos no Hugging Face sob Apache 2.0, foco direto em tarefas de agentes e uma base técnica de 400B parâmetros em arquitetura MoE, com 13B ativos por token. Essa fundação foi treinada por 33 dias em 2.048 GPUs Nvidia B300 com 17 trilhões de tokens, números que mostram o esforço de engenharia por trás da família Trinity.
Por que Trinity-Large-Thinking importa para agentes
A versão Thinking nasce explicitamente para missões de agente de longo prazo. A Arcee relata avanços consistentes em coerência multi-turnos, uso de ferramentas em sequência e aderência a restrições, pontos críticos quando um agente executa tarefas por horas ou dias. Além disso, a empresa menciona resultado de destaque no PinchBench, uma suíte de tarefas práticas voltadas a OpenClaw, onde o modelo teria alcançado a segunda colocação atrás do Opus-4.6, com preço por saída de cerca de 0,90 dólar por milhão de tokens na API, descrito como aproximadamente 96 por cento mais barato.
Esse foco conversa com uma tendência do ecossistema de agentes. O PinchBench surgiu como um benchmark de produtividade para OpenClaw, medindo sucesso em tarefas reais como agenda, pesquisa multi-fonte e fluxos de trabalho de vários passos, o que ajuda a separar modelos bons de chat de modelos bons de trabalho.
No tráfego do mundo real, o Preview serviu trilhões de tokens em pouco tempo e tornou-se um dos modelos abertos mais usados no OpenRouter nos Estados Unidos, sinal de tração do stack Trinity em cenários de agente. Esse volume foi um estresse útil para a infraestrutura de serving, e a Arcee afirma que manterá o Preview gratuito no OpenRouter, ainda que em menor capacidade, enquanto o Thinking assume o papel de modelo de raciocínio principal.
O que há sob o capô, arquitetura e dados
A família Trinity-Large é um MoE esparso em escala de 400B parâmetros, com 4 especialistas ativos entre 256 por token, o que resulta em cerca de 13B parâmetros efetivos por passo. A escolha de sparsidade extrema viabiliza custo por token mais baixo e throughput alto, sem abandonar qualidade de geração. O relatório técnico e o post de engenharia detalham ainda camadas densas adicionais para estabilizar roteamento, balanceamento de carga por momentum no roteador, uso de z-loss para conter drift de logits e ganhos de 2 a 3 vezes em throughput comparado a pares do mesmo porte.
O treino do Large Base consumiu 17 trilhões de tokens em três fases de 10T, 4T e 3T, com curadoria da DatologyAI e mais de 8 trilhões de tokens sintéticos cobrindo web, código, matemática, raciocínio e multilinguismo. O contexto nativo foi estendido para 512k, algo particularmente valioso para agentes que mantêm estado, leem documentos longos e concatenam históricos.
Para desenvolvedores e pesquisadores, a Arcee publicou três checkpoints, Preview, Base e TrueBase, todos no Hugging Face sob Apache 2.0. A página do modelo confirma a licença e descreve a topologia Afmoe, o uso de 2.048 GPUs B300, além de exemplos de uso com Transformers, vLLM, llama.cpp e integração via OpenRouter.
![Comparativo de benchmarks do Trinity Large]
O que muda entre Preview e Thinking
O Trinity-Large-Preview foi uma pós-regulação leve de instruções, pensado para testar a base em produção, ganhar feedback e estressar a camada de serving. Ele ficou gratuito no OpenRouter durante o período de prévia e seguiu competitivo em benchmarks acadêmicos como AIME 2025, MMLU e MMLU-Pro para um modelo com pós-treinamento mínimo. O Thinking dá o próximo passo, introduzindo raciocínio explícito antes da resposta final, um ingrediente que tradicionalmente eleva a precisão e a utilidade em pipelines de agente.
A diferença prática aparece em multi-turn tools, coerência em contexto extenso e aderência a instruções sob restrição, cenários típicos de OpenClaw e orquestradores similares. O próprio blog da Arcee destaca ganhos nessas frentes, além da métrica no PinchBench. Como princípio, o Thinking busca o equilíbrio, mais qualidade por token sem tornar a economia impraticável quando um agente consome bilhões de tokens por mês.
Integração, onde rodar e como começar
Para começar rápido, há duas rotas principais. Primeiro, a API da Arcee, com endpoint compatível com OpenAI e suporte a 128k no Preview enquanto a infraestrutura evolui, mantendo 512k como alvo nativo para a família. Segundo, o OpenRouter, que lista o Trinity-Large-Preview com documentação de preço e uso diário, e periodicamente adiciona variantes, incluindo a versão Thinking conforme a disponibilidade.
Para quem prefere auto-hospedar ou pesquisa, os pesos de Preview, Base e TrueBase estão no Hugging Face sob Apache 2.0, com instruções para Transformers, vLLM e llama.cpp. A página do Preview expõe ainda suporte a quantizações e exemplos de chamada via API do OpenRouter, útil para encaixar rapidamente em orquestradores e agentes já existentes.
![Throughput e latência do Trinity Large]
Custos, desempenho e trade-offs
O post da Arcee para o Thinking crava o preço de cerca de 0,90 dólar por milhão de tokens de saída em sua API e cita vantagem de custo significativa em relação a modelos proprietários de topo. Associado à arquitetura MoE esparsa, esse preço coloca o Trinity em boa posição para workloads de agente sempre ativos, que tipicamente queimam mais tokens do que chats pontuais. Em contrapartida, a linha Preview reconhece que, em janeiro, ainda não era um modelo de raciocínio, e que a transição para Thinking exigiu reforço de SFT e RL para acompanhar o porte do Base.
Há também a realidade operacional, a Arcee informa que o treino de pré-treinamento do Large terminou em 33 dias, com orçamento total de aproximadamente 20 milhões de dólares para toda a iniciativa, o que inclui compute, pessoal, dados e operações. Essa urgência moldou escolhas de engenharia, como sparsidade agressiva, técnicas de balanceamento de carga entre especialistas e extensões de contexto em fases distintas do ciclo.
Como avaliar e onde o Trinity se destaca
Benchmarks acadêmicos continuam úteis, mas para agentes o PinchBench e as métricas de uso no OpenRouter dão um cheiro mais próximo do chão. O site do PinchBench centraliza resultados e convida contribuições, e a comunidade OpenClaw discute frequentemente custo por milhão de tokens e taxas de sucesso por tarefa, indicadores práticos para escolher um modelo em produção. Nesse contexto, o Trinity-Large-Preview apareceu com alta adoção, e a versão Thinking chega para capitalizar esses sinais, priorizando raciocínio, ferramenta e coerência.
Para times de produto, o recado é direto, se o seu agente precisa manter estado por longos períodos, seguir instruções com restrições estritas e orquestrar cadeias de ferramentas sem desandar, a família Trinity now tem uma variante explicitamente otimizada para isso, com pesos abertos sob Apache 2.0, documentação de uso em frameworks populares e rota de integração via OpenRouter.
Boas práticas de adoção, passos concretos
- Validar no PinchBench, execute tarefas representativas do seu domínio e compare custo por tarefa, não apenas custo por milhão de tokens.
- Ensaiar multi-turn tool use com limites, teste cadeias longas com recuperação de contexto, chamadas de API e escrita de arquivos sob restrições.
- Explorar quantizações e servidores de inferência como vLLM e llama.cpp quando for auto-hospedar, buscando balanço entre latência e custo.
- Se o objetivo inclui pesquisa e distilação, avaliar o TrueBase como baseline pré-instrução.
- Medir estabilidade em loops longos, com heartbeats e checkpoints de estado, onde o Thinking foi treinado para aguentar a bronca.
Reflexões e insights
A chegada do Trinity-Large-Thinking mostra maturidade de um pipeline que começou com Preview e agora aciona SFT e RL em escala compatível com um MoE de 400B. O recado estratégico é que abrir pesos sob Apache 2.0 não precisa ser incompatível com performance e economia, sobretudo quando o alvo é produtividade de agentes. Se a comunidade continuar a validar o modelo em benchmarks de tarefa e em tráfego real, o círculo virtuoso de feedback pode acelerar, beneficiando até as variantes menores via distilação.
Para o mercado, o fato de um laboratório relativamente enxuto treinar um modelo dessa escala em aproximadamente um mês e com orçamento declarado de 20 milhões de dólares indica que eficiência de engenharia, sparsidade e curadoria de dados estão deslocando o debate de apenas tamanho para custo por capacidade útil. Isso pressiona preços por token, incentiva transparência de pesos e reabre espaço para inovação aplicada nos agentes, não apenas em placares sintéticos.
Conclusão
Trinity-Large-Thinking consolida a proposta da Arcee AI, pesos abertos, licença permissiva e foco em agentes de longo prazo. A base de 400B em MoE, o contexto de 512k e o pipeline reforçado de SFT e RL dão lastro técnico para a ambição, enquanto o preço por milhão de tokens e a integração via OpenRouter baixam a barreira de entrada para equipes que querem sair do laboratório e operar em produção.
O próximo capítulo está claro, levar o que funcionou no Large para Mini e Nano, distilar e manter a economia saudável. Com benchmarks de tarefa como o PinchBench e métricas de uso abertas, a comunidade terá instrumentos para julgar, comparar e orientar a evolução. A melhor forma de validar é colocar o Trinity-Large-Thinking para trabalhar em algo real, medir e iterar.