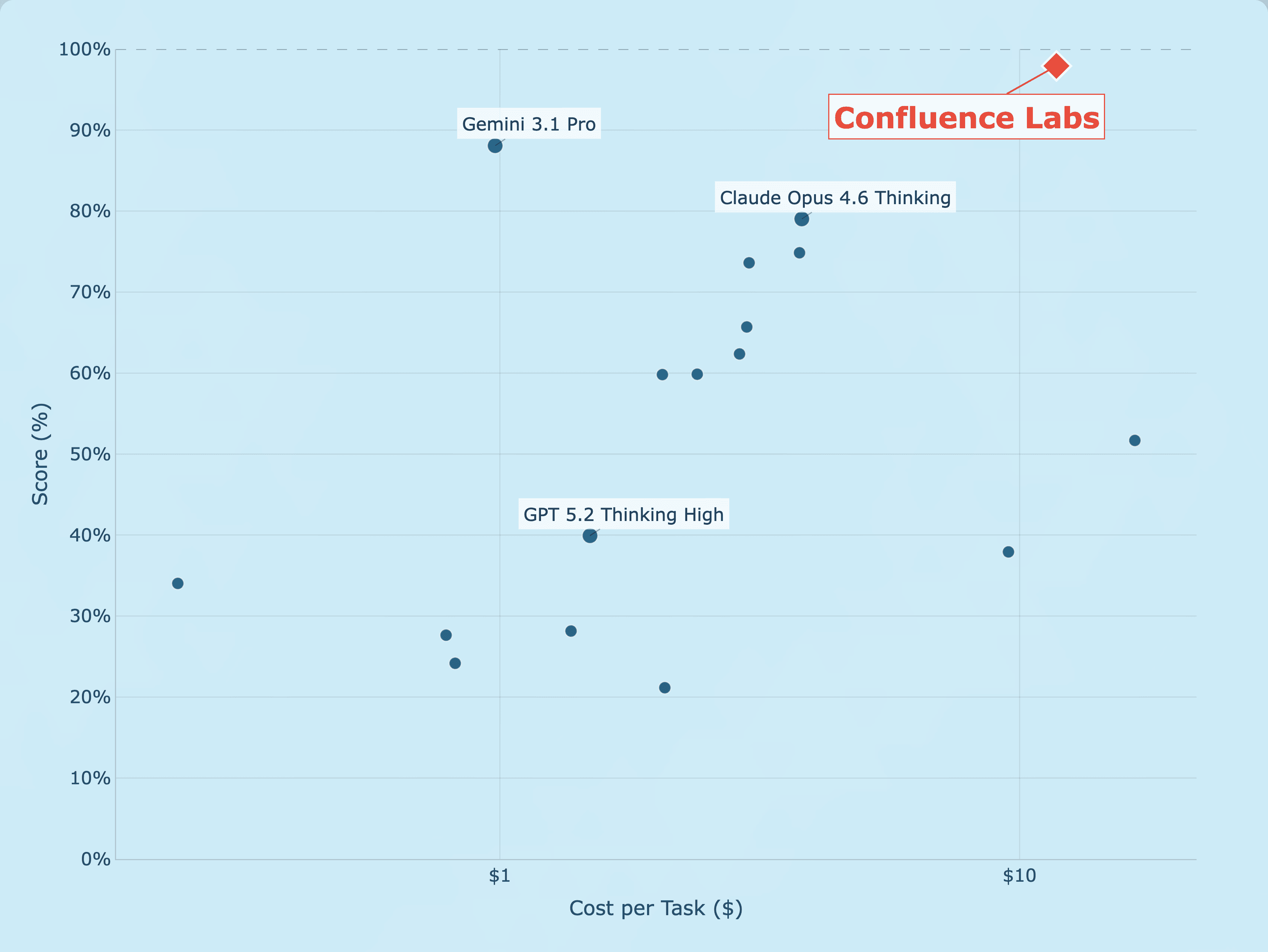
Confluence Labs sai do stealth com 97,9% no ARC-AGI-2 a US$11,77 por tarefa, ycombinator.com
Resultado de 97,9% no ARC-AGI-2 com custo de US$11,77 por tarefa coloca a Confluence Labs no radar. Entenda o benchmark, a abordagem de síntese de programas e o que isso indica para IA em domínios com poucos dados.
Danilo Gato
Autor
Introdução
Confluence Labs ARC-AGI-2 entrou no mapa de tecnologia e IA com um resultado que chamou atenção, 97,9% no ARC-AGI-2 ao custo médio de aproximadamente US$12 por tarefa no conjunto público de avaliação, tornando público o solver e posicionando o laboratório como referência em eficiência de aprendizado. O anúncio foi feito no Launch YC, com detalhes de abordagem e contexto técnico divulgados no site oficial do laboratório.
O ARC-AGI-2 é um dos benchmarks de raciocínio mais desafiadores, projetado para avaliar a capacidade de generalizar a partir de poucos exemplos. Em comparação com um ano antes, quando os melhores modelos ainda patinavam em um dígito, o novo patamar obtido pela Confluence Labs reacende discussões sobre limites de benchmarks públicos, generalização real e aplicações práticas em domínios de dados escassos.
Este artigo explica o que está por trás do resultado, o que difere no ARC-AGI-2, como a síntese de programas guiada por LLMs funciona na prática, o que o custo por tarefa realmente significa e onde essa linha de pesquisa pode acelerar P&D em hardware, biologia e materiais.
O que é o ARC-AGI-2 e por que importa
O ARC-AGI-2 é a evolução da série ARC, um conjunto de tarefas em grade com cores e regras que exigem abstração, composição de regras e raciocínio simbólico a partir de exemplos mínimos. A fundação ARC Prize estrutura o benchmark em múltiplos conjuntos, público, semi privado e privado, calibrados para que a dificuldade percebida por humanos seja similar entre eles e para torná los menos suscetíveis a overfitting. O objetivo é medir eficiência e capacidade de generalização em cenários com poucos dados e pouca possibilidade de coleta adicional.
Do ponto de vista de avaliação, o ARC-AGI-2 oferece um conjunto público de treinamento, um público de avaliação e dois níveis não públicos, semi privado e privado, usados para rankings oficiais e competições. O desenho separa exploração aberta, onde se pode iterar e publicar abordagens, da aferição mais robusta de generalização na trilha competitiva. Para equipes e empresas, isso cria um circuito, desenvolver ideia no público, validar custo e, depois, tentar confirmar ganhos no semi privado e no privado.
Em 2025, o ARC-AGI-2 consolidou status de termômetro de raciocínio entre laboratórios e comunidade, com resultados reportados em model cards e competição global, o que explica por que um salto de performance desperta tanta atenção técnica e de produto.
O anúncio, o placar e o custo por tarefa
O Launch YC destacou a saída do stealth da Confluence Labs com um solver de estado da arte, 97,9% no conjunto público do ARC-AGI-2 a cerca de US$12 por tarefa, valor comunicado como US$11,77 em materiais públicos. O laboratório também open sourceou o solver, permitindo reprodução dos resultados. Para um benchmark que mede raciocínio e eficiência, custo por tarefa é parte integrante do placar, porque força decisões de engenharia, do modelo LLM base aos laços de busca e avaliação do programa gerado.
Custo por tarefa, no contexto do ARC-AGI-2, é a média dos gastos com inferência e tentativas necessárias para resolver cada item do conjunto, típico quando se acopla um LLM a um loop de síntese de código, testes e verificação. Isso incentiva estratégias mais parcimoniosas e, em última análise, é um proxy para viabilidade econômica de usar sistemas de raciocínio em escala. Os dados de leaderboard e telemetria do ecossistema ARC Prize corroboram essa leitura.
Como a Confluence Labs chegou lá, síntese de programas guiada por LLMs
A linha mestra da abordagem é tratar o problema como síntese de programas. Em vez de perseguir diretamente a resposta final, o sistema solicita ao LLM que escreva código que implemente a transformação pedida pela tarefa, com loops de avaliação, correção e iteração. Essa estrutura tira proveito de duas forças, LLMs são extremamente bons em escrever código, e especificações explícitas de sucesso, que permitem medir progresso de forma objetiva a cada passo.
No detalhe, três princípios norteiam a solução, estruturar o problema para se parecer com a distribuição de treino do LLM, habilitar trabalho de longo horizonte, acumulando contexto e tentativas passadas, e definir critérios de solução de forma precisa, de modo que o modelo consiga se auto avaliar ao longo do ciclo. O resultado prático é um agente que propõe hipóteses na forma de código, testa contra exemplos, mensura gaps e refina a proposta, escalonando o esforço de busca sem desperdiçar chamadas de API.
Essa estratégia se conecta com uma tendência mais ampla, sistemas agentic com ferramentas, onde o LLM orquestra chamadas de ferramentas especializadas, execução em REPL e verificadores. Em competições relacionadas e análises independentes, variações agentic têm mostrado ganhos significativos de acurácia em ARC-AGI-2, reforçando que raciocínio prático emerge quando o modelo consegue experimentar, verificar e corrigir, não só quando gera uma cadeia de pensamento.
Dados, reprodução e o que o gráfico mostra
O laboratório publicou o solver em repositório público, incluindo materiais para reprodução local e gráficos de desempenho versus custo por tarefa. Reprodutibilidade é crítica em benchmarks abertos, e disponibilizar pipeline, prompts, scripts e artefatos visuais facilita escrutínio da comunidade e comparações justas com outras abordagens.
![Gráfico de performance e custo em ARC-AGI-2]
Para além do gráfico, é útil lembrar o desenho do ARC-AGI-2, o conjunto público existe para acelerar P&D e fomentar ideias, já os conjuntos semi privado e privado calibram generalização sob regras mais rígidas. À medida que pontuações públicas sobem, a referência de robustez migra para os splits não públicos, onde a probabilidade de overfitting cai. É assim que a comunidade tem interpretado progresso ao longo dos ciclos do prêmio.

E o debate sobre generalização, público versus privado
Sempre que um benchmark público é saturado, surge a pergunta, isso se transfere para o conjunto privado, para tarefas inéditas, para domínios reais com ruído e restrições? O próprio anúncio da Confluence Labs reconhece que o ARC é antes um benchmark de eficiência de aprendizado, e aponta aplicações em domínios com dados escassos, como engenharia de hardware, design de fármacos e pesquisa em física. Em outras palavras, a relevância vai além do placar, está na arquitetura que aprende com poucas amostras e no custo operacional viável.
Na dinâmica de 2025 e 2026, o ecossistema ARC reforçou o papel dos splits semi privado e privado como norte para avaliar generalização. Há registros públicos e discussões técnicas mostrando que diferenças substanciais entre público e semi privado costumam sinalizar overfitting, enquanto gaps menores sugerem maior robustez. Para times de produto, isso é um lembrete prático, validar no público é necessário, mas buscar estabilidade no semi privado e no privado é o que mitiga surpresas quando o sistema encontra dados fora da distribuição.
Aplicações práticas, onde eficiência de aprendizado vira diferenciação
O ponto central do laboratório é eficiência de aprendizado, ou seja, quantos experimentos são necessários para acertar hipóteses úteis. Em P&D de materiais, acelerar ciclos de hipótese e teste reduz ordens de grandeza em tempo de descoberta. Em drug discovery, priorizar compostos promissores com 10 a 100 vezes menos ensaios poupa budget e tempo regulatório. Em engenharia de hardware, explorar espaços de projeto com poucos protótipos físicos pode encurtar roadmaps inteiros. A Confluence Labs indica explicitamente interesse por colaborações nessas frentes.
Do lado tático, times podem começar pequeno, selecionar casos onde os dados são caros ou lentos de produzir, encapsular regras de verificação objetivas, e conectar LLMs a ambientes de execução, simuladores e suites de teste. Essa combinação permite que o sistema aprenda com pouco, meça progresso com precisão e feche o ciclo de melhoria com custos previsíveis.
O ecossistema em volta do ARC Prize e aprendizados práticos
As trilhas do ARC Prize catalisam P&D, inclusive em ambientes como Kaggle, onde soluções compactas, por exemplo modelos pequenos bem ajustados e loops agentic eficientes, já lideraram placares públicos pela relação custo benefício. Para equipes de engenharia, a lição é clara, técnicas de síntese, verificação e busca inteligente frequentemente superam força bruta quando há restrições de custo por tarefa.
Outro aprendizado é operacional, instrumentar custo por tarefa desde o início. Métricas úteis incluem chamadas de API por iteração, tempo médio de solução, taxa de reaproveitamento de hipóteses e custo marginal da próxima melhoria percentual. Em benchmarks que exigem tentativa e erro, o que separa SOTA de quase lá é a qualidade do ciclo de feedback e a disciplina de custo.
Guia rápido, como reproduzir ideias chave na sua stack
- Defina o problema como transformação verificável. Emule o formato ARC, entradas simples, saídas objetivas e uma função de avaliação clara. Crie testes mínimos mas suficientes para detectar regressões.
- Dê ao LLM ferramentas de execução. Exponha um REPL, permita rodar código com sandbox e colete logs. O LLM deve ler, escrever, compilar e testar hipóteses programáticas.
- Modele o loop de longo horizonte. Armazene tentativas, gere diffs e peça ao modelo para aprender com o histórico, reduzindo repetições inúteis.
- Otimize custo por tarefa. Meça e limite tokens por iteração, adote early stopping quando a métrica de verificação estabilizar, e priorize estratégias que aumentem a taxa de acerto por chamada.
- Valide em splits diferentes. Use um conjunto de validação fora do seu conjunto de desenvolvimento para evitar overfitting e tentar aproximar o cenário semi privado.
![Conceito visual de AI reasoning]
Reflexões e insights que valem para além do ARC
- Benchmarks, quando saturados no público, não perdem utilidade, mudam de papel, viram plataforma de engenharia para custo, latência e reprodutibilidade. O progresso passa a ser medir robustez fora do domínio, em splits fechados e, principalmente, em dados reais.
- Síntese de programas guiada por LLMs reduz ambiguidade e aumenta interpretabilidade. Código é audível, testável e versionável. Em setores regulados, isso ajuda auditorias e explicabilidade.
- Eficiência de aprendizado é alavanca econômica. Em pipelines científicos, cada experimento poupado desloca orçamento para exploração de hipóteses novas. A fronteira competitiva migra de quem tem mais dados para quem usa melhor cada exemplo.
Conclusão
Resultados como o 97,9% no ARC-AGI-2 a US$11,77 por tarefa mostram que síntese de programas, verificação rigorosa e loops agentic podem levar LLMs a resolver tarefas de raciocínio com pouco dado e custo controlado. O laboratório abriu o código e detalhou princípios, o que ajuda o ecossistema a comparar abordagens e a adaptar ideias a contextos industriais de alto impacto.
O próximo capítulo deve combinar duas frentes, consolidar essas técnicas nos splits mais rígidos do benchmark e, principalmente, traduzi las em ganhos tangíveis em P&D do mundo real. Para quem constrói produtos, a oportunidade é clara, encapsular problemas como transformações testáveis, oferecer ferramentas ao LLM e gerenciar custo por tarefa como primeira métrica de sucesso.