Google lança Gemini Deep Research e Deep Research Max com MCP e visualizações
Google apresenta os agentes Gemini Deep Research e Deep Research Max com suporte ao Model Context Protocol, visualizações nativas e foco em pesquisas longas e citadas para uso profissional.
Danilo Gato
Autor
Introdução
Google lança Gemini Deep Research e Deep Research Max com suporte a MCP e visualizações, um passo direto para colocar agentes de pesquisa autônomos no centro de fluxos corporativos. O anúncio, publicado em 21 de abril de 2026, destaca integração com o Gemini 3.1 Pro, capacidade de citar fontes e gráficos nativos nos relatórios, tudo pensado para investigações de longo prazo na web e em dados privados.
A novidade importa porque pesquisa profunda consome tempo, exige curadoria de fontes e pede síntese confiável. Com o Deep Research para experiências rápidas e o Deep Research Max para qualidade máxima e processos assíncronos, a proposta é reduzir latência, cortar custos e ampliar o rigor analítico, mantendo rastreabilidade com referências.
Este artigo explica como funcionam os novos agentes, o que muda com MCP na prática, quais benchmarks embasam as alegações de desempenho, como explorar visualizações nativas e que cuidados adotar em segurança e governança.
O que é o Gemini Deep Research, agora em duas versões
O Google descreve a evolução do agente de pesquisa em dois perfis. Deep Research prioriza velocidade e eficiência, indicado para interfaces interativas onde latência menor é essencial. Deep Research Max prioriza exaustividade, usa mais computação em tempo de execução e iteração para sínteses de maior qualidade em fluxos como due diligence noturna ou varreduras setoriais. Os dois trabalham com web aberta e fontes privadas, além de oferecer relatórios citados.
A base técnica é o Gemini 3.1 Pro, disponível na API e no ecossistema de produtos Google para desenvolvedores, o que facilita levar os agentes para pipelines existentes. O 3.1 Pro é a geração mais recente da família Gemini 3 e foi posicionado para resolver desafios modernos em ciência, pesquisa e engenharia.
Para equipes de produto, a separação em duas versões simplifica escolhas: experiências na borda, como painéis em apps, se beneficiam do modo rápido, enquanto análises offline e recorrentes ficam com o Max. Na prática, dá para orquestrar ambos em um mesmo pipeline, disparando uma coleta abrangente com o Max e um assistente interativo com o Deep Research para refinar perguntas com o usuário final.
MCP, dados proprietários e integração com ferramentas
Um dos pontos mais relevantes é o suporte ao Model Context Protocol. MCP é um padrão aberto, introduzido pela Anthropic em 2024 e hoje difundido no ecossistema de agentes, que define como modelos e assistentes se conectam de forma padronizada a ferramentas, serviços e fontes de dados externos via JSON-RPC. Isso resolve a dor de construir conectores ponto a ponto, criando uma camada comum de interoperabilidade.
Com MCP, o Deep Research pode consultar servidores MCP internos, catálogos de dados, repositórios de documentos e provedores especializados, além da web. O Google afirma que o agente aceita definições de ferramentas arbitrárias, o que o transforma de pesquisador web em um agente navegando repositórios especializados. Para equipes que já padronizaram integrações em MCP, isso acelera a adoção.
Do ponto de vista de arquitetura, MCP organiza recursos, prompts e ferramentas do lado do servidor, enquanto o host do modelo conduz a orquestração. Esse desenho facilita auditoria e controle de permissões, além de reduzir acoplamento entre o agente e fontes corporativas. Para quem está começando, vale mapear ativos de dados críticos, priorizar fontes com contratos e SLAs e publicar esses recursos como servidores MCP para consumo seguro pelo agente.
Também é importante acompanhar o debate sobre segurança. Pesquisadores apontaram vulnerabilidades em implementações MCP, com risco de execução remota de código em servidores mal configurados. A recomendação é aplicar autenticação forte, isolamento de runtime, políticas de saída de rede e revisar servidores MCP de terceiros. Equipes de segurança devem testar wrappers, injeção de prompt e autorização de ferramentas.
Visualizações nativas e relatórios citados
Outro avanço são visualizações nativas, com geração de gráficos e infográficos embutidos no relatório final. A proposta é que o agente não apenas descreva, mas também mostre dados de séries temporais, comparativos setoriais ou composições por categoria, prontos para apresentação. O post oficial exemplifica gráficos econômicos e painéis que enriquecem a análise, incluindo formatos HTML e opções citadas pelo Google.
Na rotina de pesquisa, isso reduz fricção entre análise e apresentação. Em vez de exportar números para uma planilha e depois montar gráficos manualmente, o agente já entrega um relatório com fontes citadas e visualizações consistentes. Em auditorias, a combinação de citações e visual evidencia linhagem de dados, algo cada vez mais exigido por compliance em setores como financeiro e saúde.
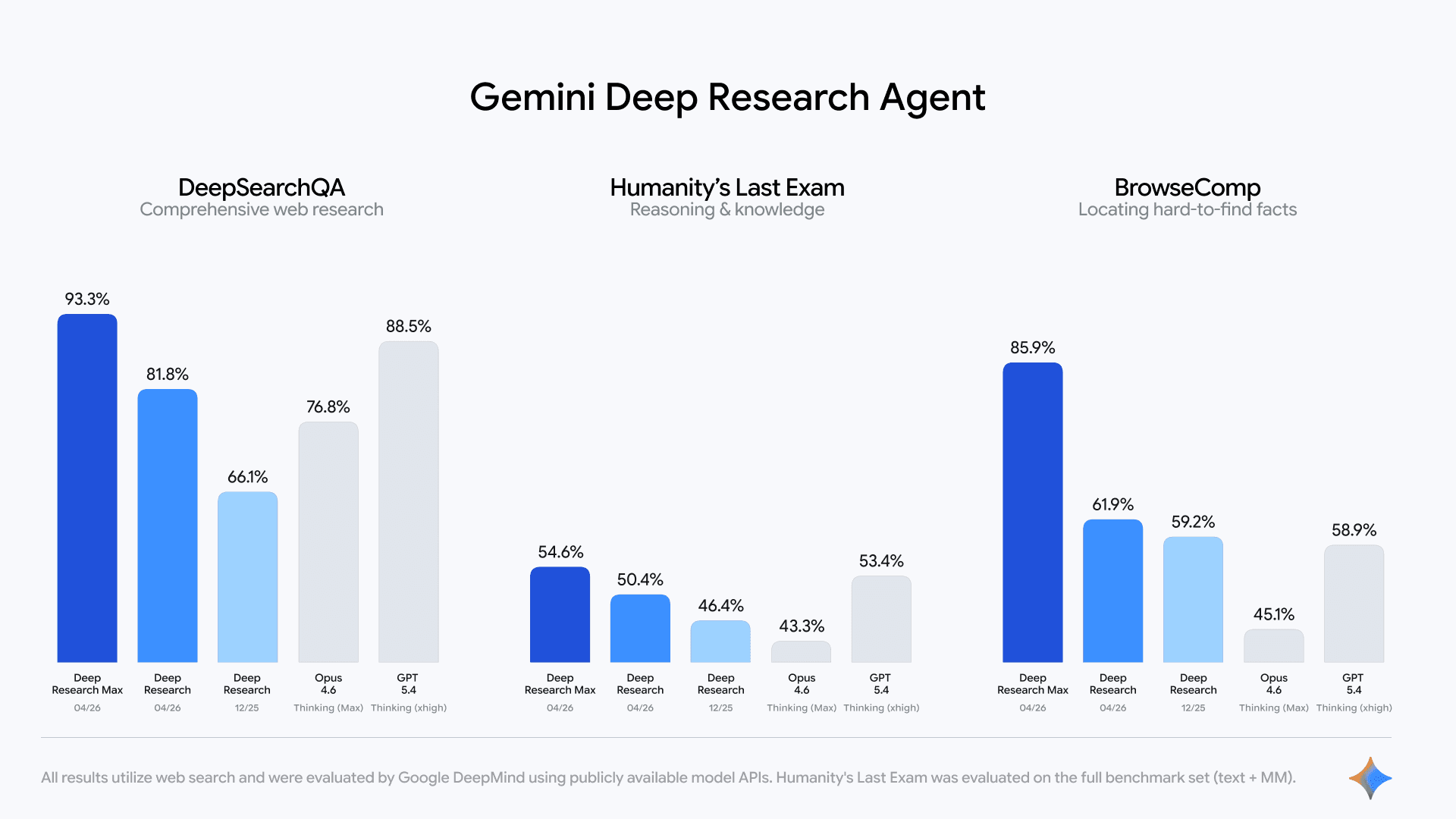
![Gráfico de desempenho do agente em benchmarks]
Legenda. O Google destaca saltos em tarefas de recuperação e raciocínio para o Deep Research e o Deep Research Max em benchmarks como DeepSearchQA, Humanity’s Last Exam e BrowseComp.
Benchmarks que importam, do DeepSearchQA ao HLE e ao BrowseComp
A validade de um agente de pesquisa depende de como se comporta em cenários difíceis. O Google cita três referências. DeepSearchQA, um benchmark de 900 prompts de busca multi etapa em 17 áreas, avalia a capacidade de conduzir pesquisas profundas com múltiplos saltos. Humanity’s Last Exam, publicado na Nature em 2026, reúne 2.500 questões difíceis e multimodais para medir conhecimento e raciocínio de alto nível. BrowseComp, proposto pela OpenAI, mede agentes de navegação que precisam persistir, reformular consultas e montar respostas a partir de pistas fragmentadas.
Por que isso interessa. DeepSearchQA expõe onde agentes falham em recuperar, cruzar e verificar. HLE pressiona raciocínio e conhecimento, evitando tarefas fáceis de memorização. BrowseComp pune agentes que desistem cedo ou que não investigam fontes alternativas. Juntos, os três dão um panorama útil para quem quer validar adoção corporativa. Há placares públicos e reavaliações contínuas, então equipes devem acompanhar resultados por versão do agente.

Aplicação prática. Em um caso de análise de mercado, o Deep Research pode levantar literatura cinzenta, filings, blogs técnicos e bancos de dados setoriais publicados via MCP. No final, compara séries temporais com gráficos nativos, cita as fontes e entrega um resumo executivo. Em ciência de dados, o Max poderia rodar sobre noites e finais de semana, coletando papers, varrendo repositórios e testando hipóteses pré definidas para acelerar a próxima sprint de pesquisa.
Onde o Deep Research se encaixa no seu stack de IA
Para desenvolvedores, a integração começa pela API do Gemini 3.1 Pro, disponível via AI Studio, Vertex AI e ferramentas como Android Studio e CLI. Com um único chamado, segundo o Google, é possível disparar fluxos de pesquisa exaustivos que combinam web aberta e dados proprietários. Times que já operam em nuvem Google podem encaixar a orquestração no Vertex e aproveitar governança, chaves gerenciadas e registro de atividades.
Para empresas multicloud, MCP ajuda a desacoplar a coleta de dados do provedor do modelo. Dá para manter seus servidores MCP em qualquer infraestrutura com políticas próprias, enquanto os agentes Gemini consomem esses recursos com autenticação, quotas e logs. Esse desenho reduz vendor lock in e facilita auditoria por domínio de dados, algo crítico em setores regulados.
Boas práticas operacionais. Defina perfis claros de uso, por exemplo, Deep Research para assistentes internos e Max para pipelines batch. Implemente testes de regressão com subconjuntos de DeepSearchQA e conjuntos internos. Crie salvaguardas para alucinações, como exigência de citação fonte a fonte, checagem automática de links e limitação de confiança quando não houver evidência. Monitore custo por relatório, latência por iteração e taxa de respostas com fontes verificáveis.
![Exemplo de visualização nativa gerada pelo agente]
Legenda. Visualizações nativas prometem transformar dados qualitativos e quantitativos em gráficos prontos para apresentação, reduzindo retrabalho entre análise e design.
Segurança, conformidade e riscos de integração
Além de vulnerabilidades em servidores MCP mal configurados, há vetores clássicos como injeção de prompt em páginas da web, data exfiltration via ferramentas e escalada de privilégios quando o agente ganha acesso a múltiplos sistemas. Adote isolamento de tool runners, listas de permissões explícitas, varredura de conteúdo com DLP e assinaturas de domínio para mitigar hijacking de fontes. Padronize avaliações de segurança específicas de MCP, seguindo recomendações acadêmicas recentes e guias corporativos.
Conformidade exige trilhas de auditoria que conectem input, ferramenta usada, fonte consultada e saída final. O desenho de relatórios citados do Deep Research ajuda nessa trilha. Times jurídicos devem revisar termos de uso de fontes, políticas de robots e scraping, além de restrições de redistribuição de dados. Se operar em países com requisitos de residência de dados, hospede servidores MCP e caches nas regiões corretas.
Estratégia de adoção, KPIs e ROI
Para medir impacto, alinhe KPIs com o tipo de pesquisa. Em descoberta científica, priorize tempo até hipótese validada, número de fontes independentes e taxa de replicação. Em mercado, foque em tempo para relatório, cobertura de fontes por segmento e custo por relatório aprovado. Em governança, monitore taxa de respostas citadas, acurácia factual em amostras auditadas e incidentes evitados por checagem automatizada.
Uma abordagem em três ondas funciona bem. Primeira, pilotos focados, com 30 a 60 dias, métricas fechadas e corpus limitado via MCP. Segunda, ampliação para times que consomem relatórios repetitivos, com Max rodando em janelas off peak. Terceira, integração com aplicativos internos, expondo o Deep Research em interfaces simples para atrair adesão com fricção mínima. Documente padrões de prompts, políticas de citação e playbooks de incidentes.
Reflexões e insights
A separação entre um agente rápido e um agente para síntese máxima atende realidades distintas de produto e de pesquisa. O suporte a MCP alinha o Google a um movimento de padronização que já vinha crescendo desde 2024, o que sugere um ecossistema mais interoperável entre agentes e ferramentas. Isso reduz custo de integração e acelera time to value.
Benchmarks como HLE e BrowseComp mudam a régua. Eles medem perseverança de busca, raciocínio e capacidade de construir respostas com evidência. O fato de o Google posicionar ganhos nesses testes indica foco não só em capacidade linguística, mas em comportamento de agente no mundo real. Para quem decide orçamento, isso se traduz em menos horas de analista em tarefas repetitivas e mais tempo em revisão crítica e decisão.
Conclusão
Os novos agentes Gemini Deep Research e Deep Research Max chegam com uma proposta clara. Conectar web e dados proprietários via MCP, entregar relatórios citados e visualizações nativas e escalar do assistente rápido ao pesquisador exaustivo. Para times que precisam de evidência e rastreabilidade, a combinação de interoperabilidade, benchmarks desafiadores e governança integrada é um avanço relevante.
O próximo passo é pragmático. Selecionar um domínio de alto valor, publicar fontes críticas como servidores MCP, definir KPIs e iniciar pilotos de quatro a oito semanas. Medir acurácia, custo e velocidade, ajustar prompts e políticas de citação e então escalar. Com disciplina e governança, o Deep Research pode virar um multiplicador de produtividade, sem abrir mão de rigor técnico e segurança.