Google lança MedGemma 1.5 e MedASR, imagens médicas e voz
Atualização do MedGemma 1.5 expande leitura de imagens médicas, enquanto o MedASR reduz erros em transcrição clínica. Entenda ganhos, casos de uso e como começar a testar com dados reais.
Danilo Gato
Autor
Introdução
O MedGemma 1.5 chegou como evolução direta do modelo multimodal da Google para saúde, e a palavra chave é MedGemma 1.5. A atualização adiciona suporte mais amplo a imagens médicas em alta dimensão, melhora tarefas de localização anatômica, comparação longitudinal de exames e traz ganhos em extração de dados de relatórios de laboratório. Em paralelo, o MedASR entra como modelo de fala para texto afinado no domínio médico, com reduções expressivas de erros em ditados clínicos.
O anúncio, publicado em 13 de janeiro de 2026, também liberou o hackathon MedGemma Impact Challenge no Kaggle, com 100 mil dólares em prêmios, além de disponibilizar pesos no Hugging Face e integração no Vertex AI. O foco é oferecer bases abertas para desenvolvedores adaptarem a fluxos e regulações locais, não um dispositivo de diagnóstico pronto para uso.
O que segue detalha os avanços técnicos, impactos práticos, pontos de atenção e passos para começar a experimentar na nuvem ou on premise, com aplicações que vão de radiologia e patologia a captura de relatórios e transcrição de voz.
O que muda no MedGemma 1.5
MedGemma 1.5 foi projetado para lidar melhor com modalidades de imagem que refletem o mundo real. Além de imagens 2D, o modelo agora interpreta volumes 3D de tomografia computadorizada e ressonância magnética, e também whole slide images de histopatologia. Em benchmarks internos, a acurácia média em achados de doença em CT sobe de 58 para 61 por cento e, em MRI, de 51 para 65 por cento. Em histopatologia, a métrica ROUGE L em casos com um único slide vai de 0,02 para 0,49, equiparando o desempenho do modelo especializado PolyPath.
Esses ganhos não aparecem isolados. Em tarefas próximas do chão de fábrica, como localização anatômica em raio X de tórax, o modelo melhora o intersection over union de 3 para 38 por cento no benchmark Chest ImaGenome. Em comparação longitudinal de raio X, a macro acurácia avança de 61 para 66 por cento no MS CXR T. No pacote, a extração de dados estruturados de laudos laboratoriais, como tipo, valor e unidade, melhora de macro F1 60 para 78 por cento.
Do ponto de vista de arquitetura de produto, há um ganho pragmático relevante. Aplicações no Google Cloud passam a trabalhar com DICOM de ponta a ponta, o que reduz a necessidade de pré processamento customizado em integrações com PACS e fluxos de radiologia. Para equipes que sofrem com pipelines frágeis, isso representa menos atritos e menor manutenção.
MedASR, a peça de voz que faltava
Nos fluxos clínicos reais, muito do conteúdo nasce em áudio. O MedASR foi afinado para vocabulário médico e, quando comparado ao Whisper large v3, reduz o word error rate em ditados de raio X de tórax de 12,5 para 5,2 por cento, e em um benchmark interno mais amplo, de 28,2 para 5,2 por cento. Em outras palavras, há 58 por cento menos erros no primeiro caso e 82 por cento menos no segundo. Esses ganhos são significativos quando cada ponto percentual de erro vira ambiguidade no prontuário.
Na prática, MedASR funciona como front end de captura, alimentando o MedGemma 1.5 para raciocínio clínico, sumarização de prontuários e preenchimento de estruturas. Essa combinação tende a reduzir o retrabalho humano em revisão de transcrições e em correções de entidades médicas, desde que se mantenham validações e checagens.
Benchmarks que importam para o mundo real
Resultados de benchmark não são o mesmo que validação clínica, e o próprio Google ressalta que os modelos são bases de desenvolvimento que requerem adaptação e validação no contexto de uso específico. Ainda assim, alguns números dão uma boa sinalização de maturidade para tarefas operacionais:
- Localização anatômica em tórax, salto de 3 para 38 por cento de IoU no Chest ImaGenome, útil em marcação automática de estruturas.
- Comparação longitudinal de raio X com macro acurácia de 66 por cento no MS CXR T, suporte a comparativos de exames em linha do tempo.
- Extração de laudos laboratoriais com macro F1 de 78 por cento, reduzindo lógica baseada em regras para PDFs e textos semi estruturados.
Em texto, também há reforço. No MedQA, um benchmark de perguntas de múltipla escolha, o 4B sobe de 64 para 69 por cento, e no EHRQA, que avalia perguntas sobre registros médicos, avança de 68 para 90 por cento. Para times que querem criar RAG sobre notas clínicas ou sumarização de prontuários, é uma base mais estável.
Casos de uso imediatos e como encaixar na arquitetura
- Radiologia de rotina. O modelo já entende DICOM no Cloud, então dá para prototipar leitura de séries de CT e MRI por fatias, com prompts que instruem o tipo de achado a detectar, e acoplar a localização anatômica em tórax. Depois, usa MedASR para capturar ditado e preencher rascunhos de laudo, com revisão humana obrigatória.
- Patologia digital. O suporte a whole slide images via patches abre espaço para triagem de regiões suspeitas e geração de rascunhos de descrições, sempre com validação por patologistas. O ganho em ROUGE L sugere melhor fidelidade descritiva como ponto de partida para fine tuning com dados do laboratório.
- Gestão de dados e interoperabilidade. A extração de valores laboratoriais com F1 maior ajuda a reduzir esforços de ETL em integrações de LIS e EHR, útil para painéis de indicadores ou alertas de anomalia.
- Captura clínica multimodal. Com MedASR para transcrição e o MedGemma 1.5 para raciocínio multimodal, fica mais fácil montar assistentes que entendem voz, texto e imagem no mesmo fluxo, por exemplo, um agente que dita, busca diretrizes e compara exames em segundos, sempre exigindo confirmação do profissional.
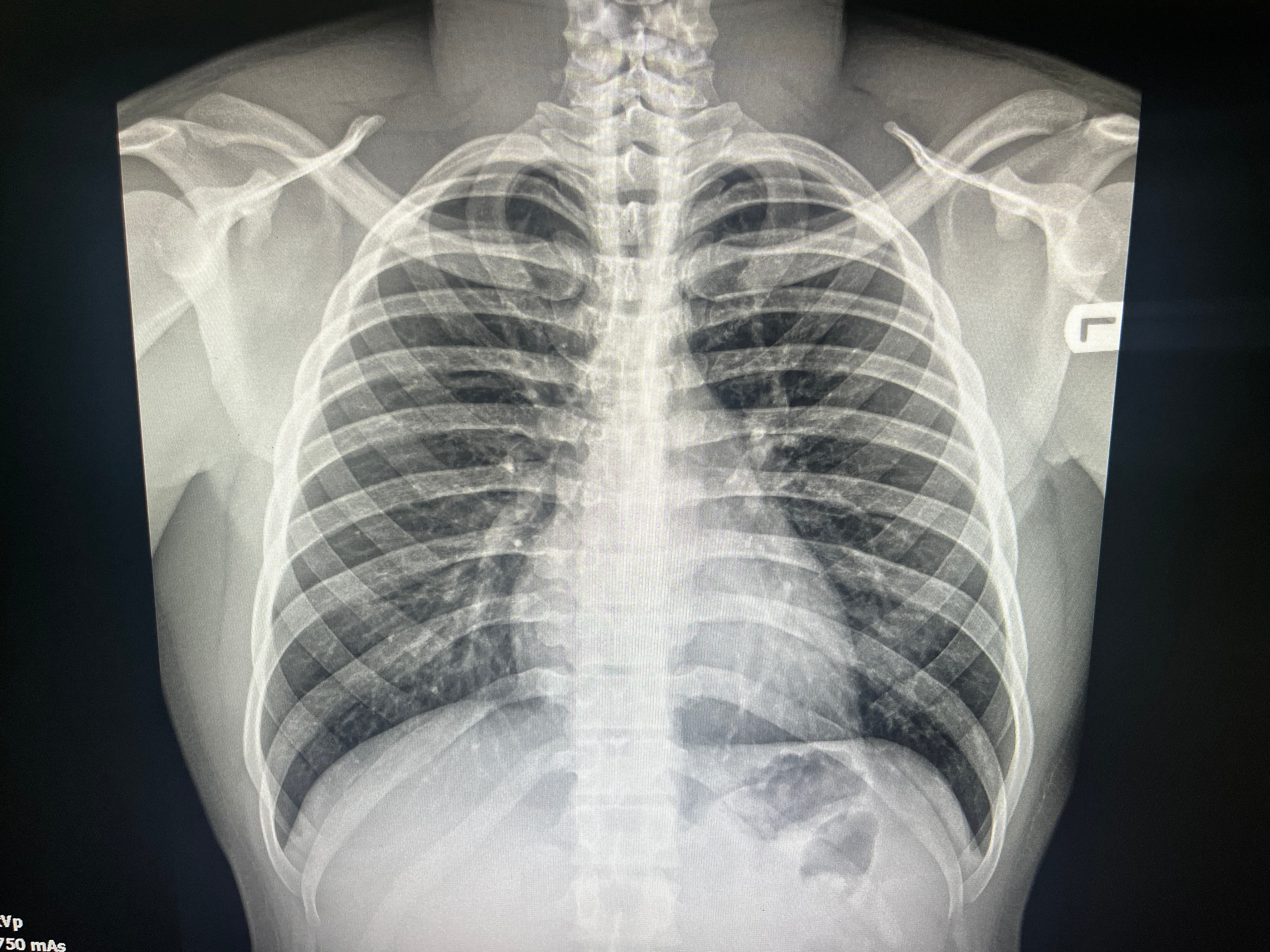
Imagem 1, anatomia do problema
![Raio X de tórax para ilustração de tarefas de localização]
A localização anatômica em radiografias de tórax é um gargalo clássico quando se tenta gerar relatórios estruturados. O salto de IoU reportado sugere que já é possível iniciar pilotos de marcação automática com revisão, reduzindo tempo de anotação e padronizando achados em pipelines de QA.
Imagem 2, o scanner no mundo real

![Tomógrafo Siemens Somatom em ambiente hospitalar]
A integração nativa com DICOM em aplicações no Google Cloud promete menos colas entre PACS, viewers e serviços de inferência. Isso diminui o risco de falhas de pré processamento, um problema comum em ambientes com múltiplos fornecedores.
Como começar, opções de deployment e custos
Para testes rápidos, os pesos do MedGemma 1.5 4B estão no Hugging Face, e a execução pode ser feita no Vertex AI. O tamanho de 4 bilhões de parâmetros foi deliberado para viabilizar execução mais barata e até offline em cenários controlados. Para tarefas textuais mais complexas, a versão 27B do MedGemma 1 segue disponível.
Em cenários hospitalares, a arquitetura mínima inclui, no front end, captura de áudio com MedASR, no meio, um serviço de inferência do MedGemma 1.5 para raciocínio multimodal, e na borda, conectores DICOM, HL7 ou FHIR para entrada e saída. O ganho vem da redução de retrabalho manual em transcrição, da padronização de relatórios e da triagem mais rápida de casos que exigem atenção.
Limites, riscos e governança clínica
Modelos de base não são dispositivos médicos. O próprio Google ressalta que os resultados são preliminares, exigem validação independente e não devem orientar decisões clínicas de forma direta. A recomendação é sempre trabalhar com ambientes de teste, comitês de revisão e auditoria de vieses, além de planos claros de fallback para erros de reconhecimento de fala, alucinações de texto e variação de qualidade de imagem.
Em dados, vale redobrar cuidados com privacidade e consentimento. O treinamento e avaliação envolvem conjuntos públicos e privados desidentificados, mas a responsabilidade de cada instituição ao adaptar o modelo inclui anonimização robusta, governança de acesso e trilhas de auditoria.
Indicadores para medir valor
- Tempo médio de ditado e revisão de laudos, antes e depois do MedASR. Reduções no WER tendem a encurtar revisão, que é onde mora o custo real.
- Precisão na extração de dados de laboratório, medida por macro F1, com spot checks por amostragem. O alvo é reduzir regras frágeis e retrabalho de digitação.
- Taxa de concordância entre localização automática e marcações humanas em tórax. O recorte por tipo de estrutura ajuda a priorizar onde investir fine tuning.
- Ganhos em tempo de triagem em patologia digital, medidos por número de campos visualizados até chegar à região relevante. O objetivo não é automatizar laudo, e sim acelerar foco e garantir consistência.
Onde a comunidade já está mexendo
A Google destaca centenas de variantes comunitárias do MedGemma no Hugging Face e milhões de downloads, sinal de interesse prático. Além disso, lançou o MedGemma Impact Challenge no Kaggle, com 100 mil dólares em prêmios, para estimular soluções de impacto em saúde e life sciences. Para equipes de produto, é uma chance de validar hipóteses com dados sintéticos ou públicos, antes de pilotar com dados institucionais.
Guia rápido de adoção em 30 dias
- Semana 1, levantar um caso alvo. Exemplo, ditado de raio X de tórax com transcrição via MedASR, sumarização inicial e checklist baseado em diretrizes.
- Semana 2, montar o pipeline. Captura de áudio, transcrição MedASR, prompts do MedGemma 1.5 com contexto local e exportação FHIR. Trabalhar em ambiente isolado, sem PHI real.
- Semana 3, medir e comparar. Coletar WER em amostras, tempo de revisão, precisão de extração de campos de laboratório, concordância em localização anatômica.
- Semana 4, ajustar e planejar validação clínica. Implementar revisão dupla, criar prompts específicos por especialidade, estudar fine tuning com dados rotulados da instituição, seguir políticas de segurança e conformidade.
Reflexões e insights
Em saúde, pequenas melhorias compostas geram grandes impactos. O que torna o MedGemma 1.5 interessante é a combinação de suporte a imagens 3D, ganhos consistentes em tarefas de chão de fábrica e um modelo de 4B que cabe em orçamentos realistas de inferência. Com o MedASR, a captura de conteúdo fica menos frágil e a curva de adoção cai. A oportunidade é construir assistentes que liberam tempo clínico, sem atropelar governança.
Outro ponto é a arquitetura de dados. A presença de DICOM no caminho oficial simplifica bastante a vida de quem integra sistemas heterogêneos. Isso não elimina o trabalho em segurança, logging e explainability, mas reduz fricções típicas de POCs. O caminho de valor passa por pilotos com metas claras, validação rigorosa e participação ativa dos times clínicos.
Conclusão
MedGemma 1.5 e MedASR sinalizam uma fase mais pragmática da IA em saúde, com ganhos em tarefas que realmente consomem horas de equipe. Não é promessa de automação total. É um kit de desenvolvimento mais competente para acelerar triagem, organização de informação e captura de conteúdo, com humanos no comando.
O próximo passo está em pilotos curtos com métricas objetivas, validações sérias e design focado em fluxo de trabalho. Quem souber combinar voz, imagem e texto com responsabilidade vai colher resultados mensuráveis sem abrir mão da segurança do paciente.