Liquid AI lança LFM2.5 Retrievers para busca multilíngue rápida
Dois novos retrievers bidirecionais, um denso e outro late‑interaction, chegam com latência baixa, suporte a 11 idiomas e índices compactos para RAG e search em escala
Danilo Gato
Autor
Introdução
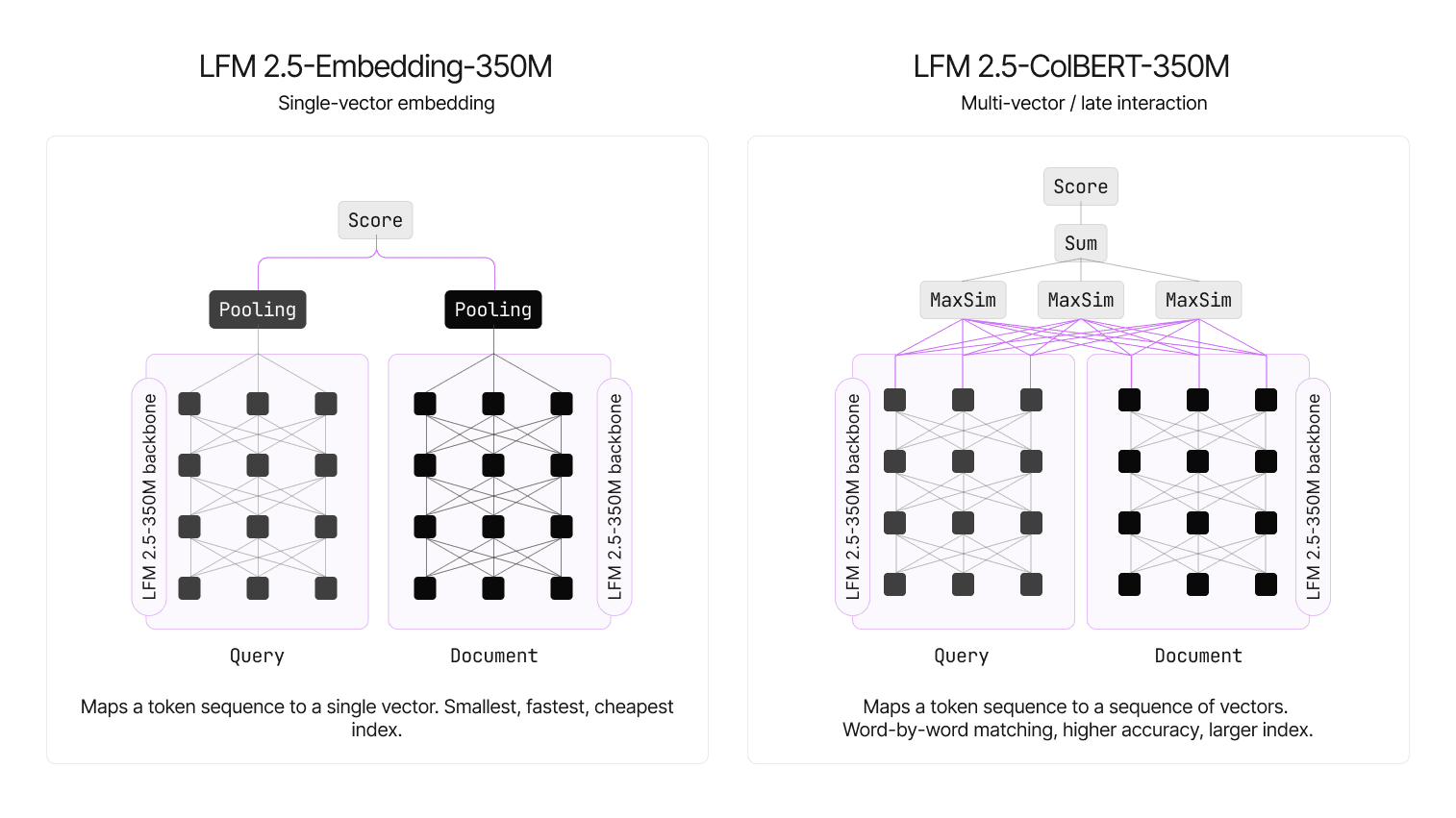
LFM2.5 Retrievers é a novidade da Liquid AI para busca multilíngue rápida em 11 idiomas, com dois modelos de 350M parâmetros pensados para RAG e search que exigem latência baixa e índices eficientes. Anunciados em 18 de junho de 2026, os modelos chegam em duas variantes, LFM2.5‑Embedding‑350M, bi‑encoder denso, e LFM2.5‑ColBERT‑350M, late interaction com MaxSim.
A proposta é direta, permitir busca confiável em catálogos, FAQs e bases curtas com footprint pequeno o bastante para rodar em laptops, servidores modestos e até borda, sem abrir mão de qualidade. Os modelos são os primeiros membros bidirecionais da família LFM e derivam do checkpoint LFM2.5‑350M‑Base, adaptado para encoder bidirecional.
O que muda com retrievers bidirecionais
Retrievers tradicionais de LLMs causais herdam uma limitação, a máscara de atenção só olha para a esquerda, ótima para geração, menos natural para entender um documento inteiro ao mesmo tempo. Os LFM2.5 Retrievers aplicam patches bidirecionais, trocam a máscara causal por atenção completa e tornam não causais as convoluções curtas do backbone LFM2. Resultado, cada token usa contexto à esquerda e à direita, algo essencial em recuperação semântica.
Na prática, isso preserva a eficiência do backbone LFM2, porém entrega representações mais ricas para tarefas de recuperação. É essa base comum que se bifurca em duas estratégias de indexação e busca, refletindo necessidades diferentes de produto e infraestrutura.
Dois caminhos, um objetivo
- LFM2.5‑Embedding‑350M, transforma cada documento em um único vetor 1024‑dim, indexa rápido, ocupa pouco espaço e tem o menor custo por consulta. Ideal para catálogos grandes, FAQs e suporte, onde escala e preço são críticos.
- LFM2.5‑ColBERT‑350M, gera vetores por token e usa MaxSim para casar consulta com termos do documento. Aumenta o tamanho do índice, porém melhora a precisão e a generalização, bom quando a qualidade manda mais do que armazenamento.
Ambos suportam os 11 idiomas listados, inglês, espanhol, alemão, francês, italiano, português, árabe, sueco, norueguês, japonês e coreano, e compartilham a janela de 512 tokens para documentos e 32 para consultas nas configurações apresentadas.
![Arquitetura, patches bidirecionais no LFM2]
Treino em três estágios, com foco em multilinguismo
Os dois retrievers seguem a mesma receita de treino em três fases, pré‑treino contrastivo em inglês, distilação multilingue e cross‑lingual a partir de um professor forte cobrindo os 11 idiomas, e fine‑tuning final com hard negatives minerados. O Embedding recebe um pouco mais de dados cross‑lingual, já que no ColBERT essa habilidade emerge naturalmente do esquema de interação tardia.
A equipe cita inspiração em pipelines que separam pré‑treino amplo de especializações tardias, como releases LateOn e DenseOn da LightOn. A combinação de dados internos curados com conjuntos de retrieval abertos e expansão via tradução conduzida por LLM amplia a cobertura de pares query‑documento em vários idiomas.
Benchmarks que importam para produto
Para avaliar robustez em multilinguismo e capacidade cross‑lingual, a Liquid AI reporta dois conjuntos, NanoBEIR Multilingual Extended, métrica NDCG@10, e MKQA‑11, Recall@20. Em NanoBEIR, LFM2.5‑ColBERT‑350M atinge média 0,605 e o Embedding 0,577, superiores a Qwen3‑Embedding‑0.6B, 0,556, e a variantes LightOn e GTE ModernColBERT nas médias reportadas. Em MKQA‑11, Recall@20 médio fica em 0,694 para o ColBERT e 0,691 para o Embedding, acima de gte‑multilingual‑base, 0,675.
Além das médias, a consistência por idioma chama atenção. Em inglês, espanhol, francês, italiano e português, ambos os modelos mantêm competitividade e, no ColBERT, a vantagem aparece justamente onde consultas exigem matching mais fino por termo. Essa coerência reduz surpresas quando o tráfego real é distribuído globalmente.
Latência, custo e onde rodar
A Liquid AI disponibiliza arquivos GGUF para rodar em llama.cpp, o que facilita execução em CPU, notebooks e edge, útil quando dados não podem sair do dispositivo. Em MacBook M4 Max, BF16, consulta de 32 tokens e documento de 256 tokens, as medições indicam p50 de 7,3 ms para o Embedding e 8,1 ms para o ColBERT na etapa de embedding de consulta. Com MaxSim no ColBERT, p50 de 8,2 ms e p95 de 15,2 ms, ainda viável para experiências responsivas.
Para cargas de produção sob alta concorrência, a pilha interna em GPU H100 reporta latências de 1,3 a 2,8 ms nas etapas de embedding e MaxSim, e cerca de 22,8 ms no caminho completo com embeddings de consulta e documento mais MaxSim. Esse perfil dá margem para orquestrar re‑rankers ou filtros de política sem comprometer SLA.
![Comparação de índices, denso vs late interaction]
Quando escolher cada retriever
- Escolha o LFM2.5‑Embedding‑350M quando o índice precisa ser mínimo e o custo por consulta é a prioridade, por exemplo, catálogos de e‑commerce em vários idiomas e bases de suporte com milhões de itens. As consultas criam um vetor, a busca roda em ANN e você controla latência com dimensionamento horizontal simples.
- Opte pelo LFM2.5‑ColBERT‑350M quando a precisão manda, como em assistentes de conhecimento internos, jurídico, financeiro e técnico, ou em buscas com linguagem ambígua. O MaxSim ajuda a casar nuances da consulta aos termos do documento e reduz erros de semântica frouxa.
Uma estratégia comum em produção combina os dois, bi‑encoder barato como estágio de recuperação inicial e ColBERT como reranker leve, equilibrando custo, latência e qualidade sem depender de um LLM grande a cada clique. Os próprios cards de modelo mostram que o ColBERT pode atuar como reranker isolado quando necessário.
Integração prática com seu pipeline
Os LFM2.5 Retrievers são compatíveis com ecossistemas populares. Há exemplos com sentence‑transformers para o bi‑encoder, e com PyLate para o ColBERT incluindo indexador PLAID. Abaixo, um exemplo conciso para iniciar o ColBERT e indexar documentos, material de referência está nos model cards.
from pylate import indexes, models, retrieve
# Carregar o ColBERT com patches bidirecionais
model = models.ColBERT(
model_name_or_path="LiquidAI/LFM2.5-ColBERT-350M",
trust_remote_code=True,
)
model.tokenizer.pad_token = model.tokenizer.eos_token
# Criar índice PLAID
index = indexes.PLAID(index_folder="pylate-index", index_name="index", override=True)
# Indexar documentos
docs = ["documento 1", "documento 2", "documento 3"]
emb_docs = model.encode(docs, is_query=False, batch_size=32)
index.add_documents(documents_ids=["1","2","3"], documents_embeddings=emb_docs)
# Recuperar top‑k
retriever = retrieve.ColBERT(index=index)
emb_queries = model.encode(["pergunta sobre documento 3"], is_query=True)
scores = retriever.retrieve(queries_embeddings=emb_queries, k=5)
Para quem precisa do menor atrito possível, a rota GGUF, com quantizações suportadas por llama.cpp, permite colocar o retriever ao lado do aplicativo em CPU ou NPU, útil em privacidade, baixa conectividade ou custos de nuvem apertados.
Casos de uso, do catálogo ao desktop
- E‑commerce global, busca semântica de produtos e atributos em vários idiomas, com controle de custo por consulta no bi‑encoder, e rerank com ColBERT em páginas críticas como resultados acima da dobra.
- Atendimento e suporte, FAQs e knowledge bases públicas, onde o Embedding mantém o índice compacto e a experiência responsiva mesmo sob picos.
- Assistentes corporativos, recuperação de políticas, manuais e relatórios, com ColBERT elevando o recall útil quando o jargão varia entre áreas.
- On‑device search, arquivos, e‑mails e notas locais, cenário favorecido pelos binários GGUF e latência baixa em hardware de consumo.
Como ficar de olho no ecossistema LFM2.5
O lançamento dos retrievers segue uma linha consistente de releases orientadas a eficiência e execução local, como LFM2.5‑350M, foco em extração confiável e tool use, e o LFM2.5‑8B‑A1B, MoE com parâmetros ativos reduzidos pensado para dispositivos e edge. Para planejamento de roadmap, vale acompanhar o blog da Liquid AI, os cards de modelo e a documentação oficial.
Recomendações de adoção
- Mapeie consultas reais por idioma e tema. Se a distribuição concentrar em 3 a 5 idiomas, teste índices separados e um fallback global. Use NanoBEIR Multilingual Extended como referência de avaliação, e MKQA‑11 para cenários de QA aberto cross‑lingual.
- Inicie com o Embedding para o estágio de recuperação e habilite ColBERT como reranker em endpoints que geram mais receita ou risco. Monitore custo por consulta e p95 de latência após cada mudança de threshold.
- Para workloads sensíveis, priorize a rota GGUF em dispositivos locais, aproveitando latências medidas e a simplicidade operacional do llama.cpp. Em data centers, explore o stack de GPU reportado para micro‑latências.
Perguntas frequentes rápidas
- Quais idiomas são suportados? Inglês, espanhol, alemão, francês, italiano, português, árabe, sueco, norueguês, japonês e coreano.
- Como escolher entre denso e late interaction? Priorize denso para custo e footprint, escolha late interaction quando precisão e generalização pesam mais que armazenamento.
- Existem exemplos de fine‑tuning? O card do Embedding inclui snippets com sentence‑transformers e orientação de treino com MultipleNegativesRankingLoss.
Conclusão
Os LFM2.5 Retrievers colocam busca multilíngue e cross‑lingual de alta qualidade ao alcance de times que precisam equilibrar custo, latência e cobertura global. A combinação de encoder bidirecional, índices compactos e disponibilidade em GGUF reduz atrito de adoção em RAG e search, do laboratório ao produto.
O momento favorece arquiteturas especializadas que convivem com LLMs maiores como orquestradores. Com o LFM2.5‑Embedding‑350M e o LFM2.5‑ColBERT‑350M, a Liquid AI oferece um par de ferramentas pragmáticas para encontrar o que importa, no idioma certo, no tempo certo, com controle de custo desde o primeiro milhão de buscas.