Liquid AI LFM2-2.6B-Exp supera instrução, conhecimento e matemática
O novo LFM2-2.6B-Exp foca eficiência e qualidade no edge, com ganhos sólidos em instrução, conhecimento e matemática, desafiando modelos maiores em benchmarks práticos.
Danilo Gato
Autor
Introdução
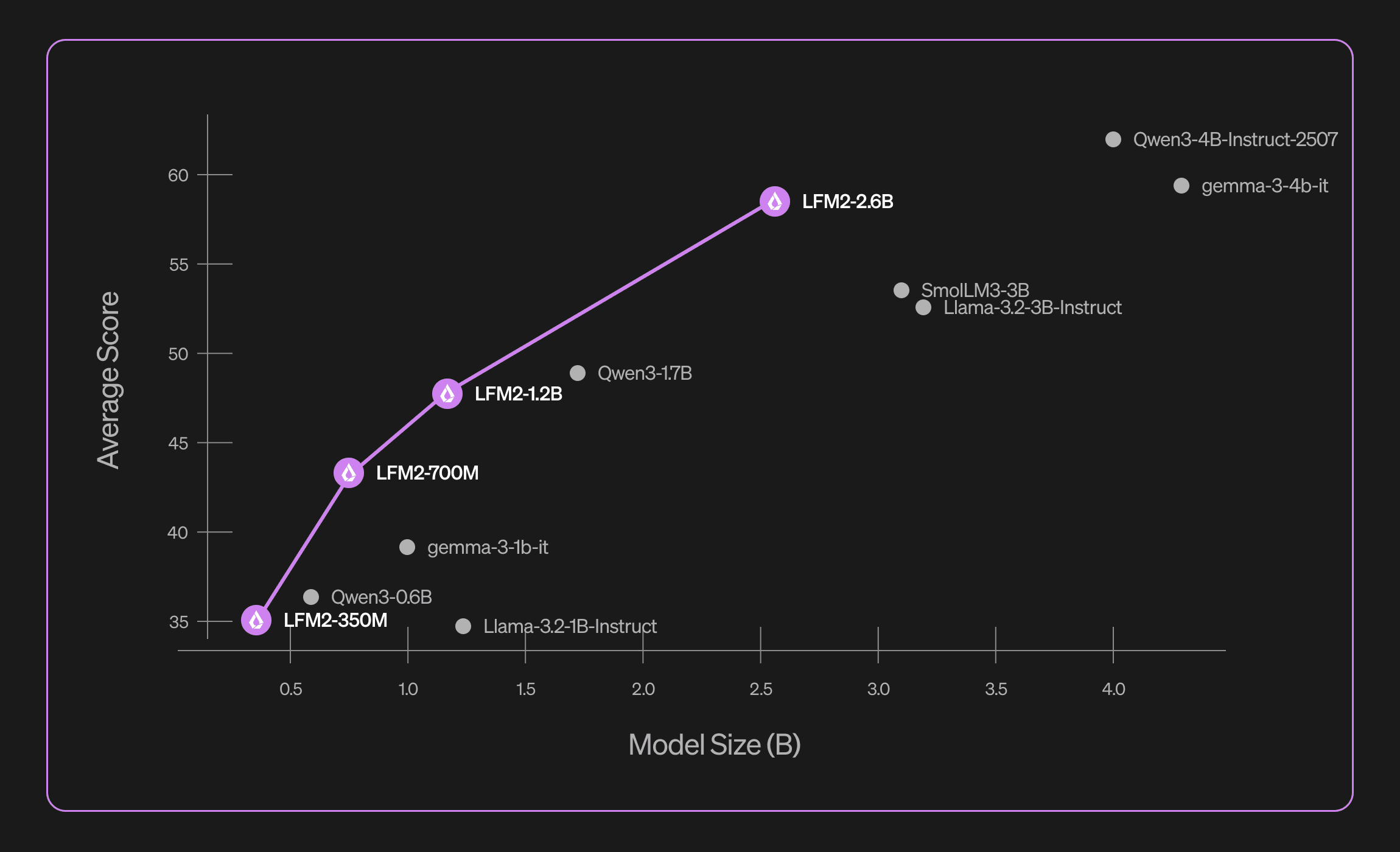
LFM2-2.6B-Exp é a palavra-chave em pequenas arquiteturas que batem acima da categoria. O novo modelo da Liquid AI aparece com 2,6 bilhões de parâmetros, mas entrega resultados fortes em instrução, conhecimento e matemática, disputando espaço com modelos maiores e conhecidos do mercado. A própria Liquid reporta 79,56 por cento no IFEval e 82,41 por cento no GSM8K, além de 64,42 por cento no MMLU, números que colocam este 2,6B na conversa com Llama 3.2 3B, Gemma 3 4B e SmolLM3 3B.
O interesse vai além dos scores. A proposta é eficiência real no edge, com arquitetura híbrida e recursos pensados para rodar bem em CPU, GPU ou NPU, reduzindo latência e custo operacional sem sacrificar a qualidade. Os posts técnicos e o card no Hugging Face detalham o contexto de treinamento, a janela de contexto de 32.768 tokens e como o time equilibra qualidade com footprint de memória.
Este artigo aprofunda benchmarks, arquitetura, trade-offs e casos de uso, com dados recentes das publicações da Liquid AI e de fontes de mercado.
O que muda com o LFM2-2.6B-Exp nos benchmarks
Os números chamam atenção em três frentes cruciais para uso prático de modelos pequenos: instrução, conhecimento e matemática. Em IFEval, o LFM2-2.6B-Exp marca 79,56 por cento. Em GSM8K, 82,41 por cento. Em MMLU, 64,42 por cento. A comparação direta feita pela própria Liquid coloca o 2,6B na dianteira ou empatado tecnicamente com modelos entre 3B e 4B em várias provas, como Llama 3.2 3B Instruct, Gemma 3 4B IT e SmolLM3 3B.
No cartão do modelo, a tabela resume bem o cenário: o LFM2-2.6B supera Llama 3.2 3B em IFEval e MMMLU, fica com GSM8K alto e competitivo, e apresenta resultado sólido de 55,39 por cento em MMMLU, o que indica que não é apenas um modelo para inglês. Ao mesmo tempo, Qwen3 4B ainda puxa vantagem em alguns marcadores, como MMLU e IFEval absolutos, o que reforça que o 2,6B-Exp lidera no equilíbrio de eficiência com qualidade, não em todas as métricas de forma isolada.
Para referência de teto, a própria família LFM2 traz um 8B Mixture-of-Experts focado em on-device, que empurra GSM8K a 84,38 por cento e IFEval a 77,58 por cento, mostrando o quanto o design escala. Ainda assim, o 2,6B mantém um pacote muito competitivo considerando custo, memória e latência, o que faz diferença na prática.
![Benchmark por tamanho de modelo, com LFM2-2.6B em destaque]
Arquitetura híbrida para velocidade e memória
O LFM2-2.6B usa um desenho híbrido que alterna blocos de attention com GQA e camadas curtas de convolução. O objetivo é reduzir KV cache, melhorar prefill e decode, e entregar uma execução mais leve no edge. Na documentação de lançamento do LFM2, a Liquid descreve ganhos de até 2 vezes em decode e prefill em CPU frente a Qwen3, além de uma infraestrutura de treinamento com eficiência 3 vezes maior que a geração anterior.
No card oficial do 2,6B, constam ainda detalhes práticos que interessam a quem implementa: 32.768 tokens de contexto, recomendação de parâmetros de geração para respostas mais estáveis, e suporte explícito a ferramentas com formatação específica de tokens, algo útil para agentes leves. O 2,6B também é o único da família com raciocínio híbrido dinâmico por meio de tokens de pensamento, ativado para prompts mais complexos ou multilíngues.
O resultado prático é um modelo que aponta para uma linha de projeto menos dependente de escala bruta e mais dependente de operadores estruturados. Na leitura dos materiais técnicos, isso explica por que a família LFM2 briga bem em várias provas com menos parâmetros, especialmente quando o foco é latência, footprint e consistência de instruções.
Onde ele realmente brilha no mundo real
Em tarefas de instrução e fluxo de trabalho, o LFM2-2.6B-Exp tem atributos que dão vantagem competitiva. O IFEval alto indica maior adesão a formatos e regras, o que é fundamental para automações, agentes de atendimento e extração estruturada de dados. Em matemática, o GSM8K acima de 80 por cento favorece cenários de backoffice com validações numéricas e cálculo step by step. Em conhecimento geral, o MMLU é sólido para o porte do modelo, embora soluções de 4B como Qwen3 mantenham vantagem média. O ponto é que o 2,6B equilibra tudo isso com latência e custo menores.
No edge, esse pacote é valioso. A Liquid enfatiza execução eficiente em CPU, GPU e NPU, com melhorias claras em throughput. Para quem precisa rodar localmente por compliance, privacidade ou custo de nuvem, o 2,6B-Exp atende sem exigir hardware caro. Isso encaixa em smartphones, laptops e até veículos, segundo a documentação.
Para quem lida com multimodalidade, vale notar que a família também inclui o LFM2-VL-3B, um parente voltado a visão e linguagem com resultados consistentes em benchmarks como MM-IFEval e RealWorldQA, mantendo linguagem geral comparável ao backbone 2,6B. Para pipelines que precisam de OCR e compreensão visual leve, essa peça complementa bem.
Trade-offs e limites, com os pés no chão
Modelos pequenos trazem limites naturais. A própria Liquid sugere uso direcionado e fine-tuning para casos específicos, além de não recomendar o 2,6B para tarefas profundamente intensivas em conhecimento ou programação pesada, algo típico de LLMs médios ou grandes. Em cenários que demandam código avançado ou raciocínio de longo prazo, 4B a 8B podem levar vantagem, inclusive dentro da própria linha LFM2.
Outro ponto é a variação entre benchmarks. Em algumas provas, concorrentes como Qwen3 4B mantêm liderança, principalmente em MMLU e IFEval absolutos. Ainda assim, quando a régua é desempenho por parâmetro e por watt, a leitura do conjunto favorece o LFM2-2,6B-Exp. Ou seja, a decisão não é só quem tem o maior score, é quem entrega o melhor pacote quando o objetivo é rodar no dispositivo com qualidade suficiente.
Disponibilidade, licença e ecossistema
O LFM2-2.6B está disponível no Hugging Face sob a LFM Open License, com pesos públicos e documentação de execução em Transformers, vLLM e llama.cpp. Também há notebooks e guias de SFT e DPO para ajuste fino rápido. Para equipes que precisam validar antes, há playground e app móvel Apollo.
No plano estratégico, a Liquid AI ganhou tração com uma rodada de 250 milhões de dólares liderada pela AMD, anunciada em 13 de dezembro de 2024, com parceria para otimização em GPUs, CPUs e NPUs da fabricante. Isso ajuda a explicar a ênfase em edge e a entrega de binários e caminhos de execução nativos nos principais toolchains.
![Imagem oficial do LFM2-2.6B]
Como aplicar bem o LFM2-2.6B-Exp hoje
- Agentes de apoio interno. IFEval alto geralmente se traduz em melhor aderência a políticas e formatos. Em service desks e bots de backoffice, isso reduz retrabalho e aumenta a confiança em respostas padronizadas. Com fine-tuning leve, o 2,6B-Exp tende a se alinhar rápido a glossários e estilos internos.
- Extração e transformação de dados. A combinação de instrução forte e latência curta facilita pipelines de ingestão, classificação e normalização que rodam localmente por requisitos de privacidade.
- Aplicações móveis e embarcadas. Janela de 32K e footprint otimizado são bons para resumos locais, assistentes de produtividade, copilotos de tarefas e suporte offline.
- Matemática e validação. GSM8K alto oferece confiança para step-by-step supervisionado, checagem de cálculos e validação de planilhas em fluxos internos.
Como comparar com o que você já usa
Uma leitura prudente é olhar não só scores brutos, mas latência por requisição, memória em execução e custo de energia no dispositivo alvo. A Liquid publica comparativos de throughput em CPU e referências de implantação em toolchains populares, o que facilita ensaios controlados. Em ambientes com output limitado a poucos milhares de tokens, a vantagem de um 2,6B enxuto pode superar a precisão marginal extra de um 4B, desde que a tarefa não exija conhecimento enciclopédico.
Para times que já usam Llama 3.2 3B, Gemma 3 4B ou SmolLM3 3B, vale rodar uma bateria de prompts reais, com logs de latência e consumo. Em instrução e matemática, os gráficos e tabelas oficiais já sugerem vantagem do LFM2-2,6B-Exp em muitos cenários. Em conhecimento puro, alguns 4B ainda vencem, então a escolha depende da mistura de tarefas da operação.
Reflexões e insights para a próxima onda de edge AI
A sinalização mais forte que sai do 2,6B-Exp é que a eficiência está se tornando vantagem estratégica. Em um ciclo de hardware diverso, de NPUs móveis a CPUs otimizadas, modelos que equilibram qualidade, latência e memória vão habilitar experiências mais fluidas e privadas. Os dados publicados pela Liquid indicam que já dá para competir com 3B e 4B sem depender de nuvem para tudo, o que muda o desenho de produtos e custos.
Outro ponto interessante é o ecossistema. Ao abrir pesos e documentar caminhos de execução e fine-tuning, a Liquid reduz atritos de adoção. Isso acelera experimentos, fomenta a comunidade e cria um ciclo de feedback que tende a melhorar o modelo, especialmente em nichos como OCR leve e agentes que precisam de tool use consistente.
Conclusão
Os números do LFM2-2.6B-Exp mostram um avanço concreto em instrução, conhecimento e matemática para um modelo pequeno. A arquitetura híbrida, somada ao foco em eficiência, coloca a família LFM2 como referência para workloads no edge que precisam de boa qualidade com latência e custo controlados. Em muitos cenários, isso vale mais que buscar o topo absoluto de precisão a qualquer preço.
O movimento também aponta para onde o mercado está indo. Com financiamento robusto e parcerias de hardware, a Liquid AI sugere um roadmap consistente para empurrar modelos pequenos a novos patamares. Para quem constrói produtos, o recado é claro. Teste no seu contexto, meça latência, memória e custo. Se a tarefa se encaixa no perfil do 2,6B-Exp, há ganho estratégico na borda.