Mistral lança Voxtral TTS, TTS multilíngue de baixa latência
Voxtral TTS chega com 4B de parâmetros, 9 idiomas, arquitetura voltada a baixa latência e preço por API agressivo, mirando agentes de voz em produção e integrações com Voxtral Transcribe para speech-to-speech.
Danilo Gato
Autor
Introdução
Voxtral TTS é o novo modelo de texto para fala multilíngue da Mistral AI, pensado para agentes de voz com baixa latência e escalabilidade. A empresa detalhou que o sistema opera com cerca de 4 bilhões de parâmetros, suporta 9 idiomas e foi projetado para iniciar a fala rapidamente em cenários de streaming, com arquitetura baseada em transformer e componentes específicos para áudio. Também está disponível via API por 0,016 dólar a cada 1 mil caracteres e com pesos abertos para pesquisa, o que acelera adoção por equipes de produto e de P&D.
A relevância vai além do anúncio. O momento do ecossistema de voz pede respostas em tempo quase real, com naturalidade e controle de emoção, algo que até pouco tempo exigia pipelines complexos ou serviços proprietários caros. A proposta do Voxtral TTS encaixa na tendência de agentes conversacionais realmente úteis, quando combinado ao Voxtral Transcribe para fechar o ciclo de speech-to-speech com latência reduzida.
O que este artigo aborda
- Como o Voxtral TTS foi construído para baixa latência e naturalidade
- Quais recursos práticos ele entrega para agentes de voz
- Dados de desempenho, idiomas, preço e arquitetura
- Comparativos e contexto de mercado, incluindo concorrentes e pesquisas recentes
Por que Voxtral TTS importa agora
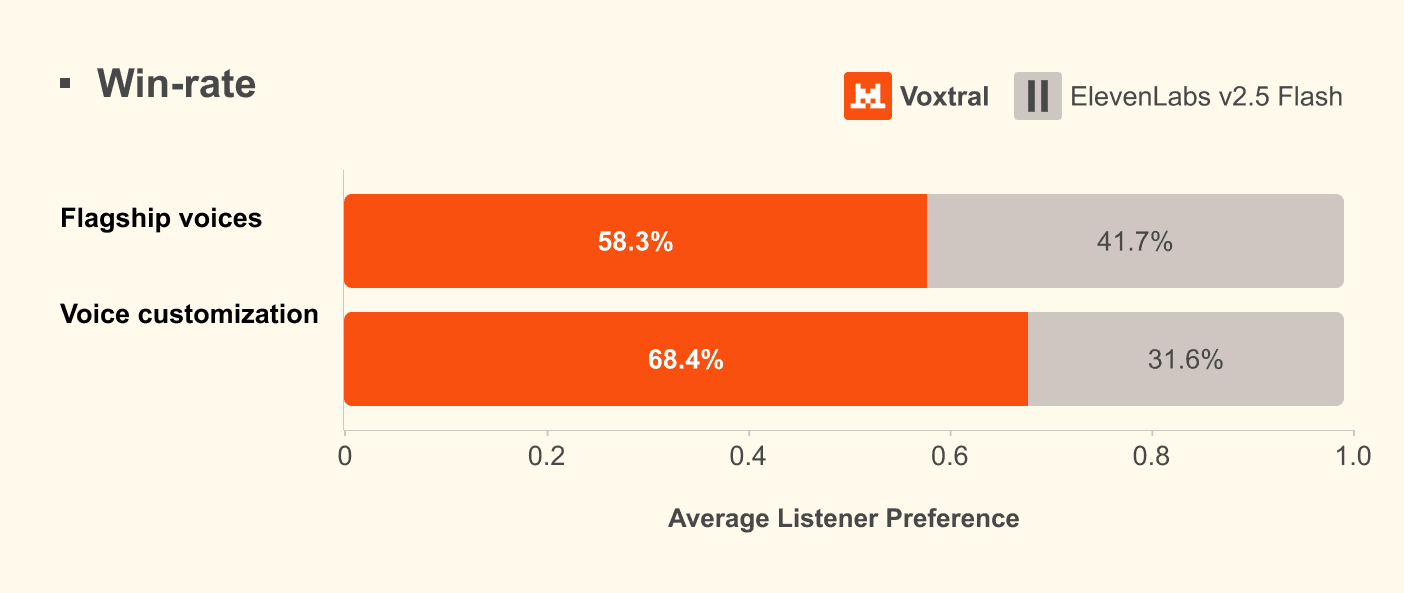
A disputa por agentes de voz úteis está sendo definida por três fatores, qualidade, custo e latência. Metrificar só pela qualidade de áudio ou WER nunca contou a história completa, porque naturalidade e adequação cultural são percebidas por humanos, não por métricas automáticas. A Mistral publicou avaliações humanas comparando Voxtral TTS com ElevenLabs Flash v2.5, destacando preferência de ouvintes em naturalidade, aderência de sotaque e similaridade acústica, mantendo tempos de início de áudio semelhantes. Esse desenho atende o que mais pesa em agentes, resposta rápida o suficiente para não quebrar o fluxo de conversa e timbre que inspira confiança.
No bolso, o preço público por API indicado é de 0,016 dólar a cada 1 mil caracteres. Para operações com alto volume de chamadas, isso ajuda a prever o custo por interação e a testar vários prompts de voz sem estourar orçamento. O modelo ainda está disponível com pesos abertos sob licença CC BY NC 4.0, o que sinaliza abertura para pesquisa, benchmarking e possíveis integrações locais em cenários não comerciais.
Arquitetura e desempenho em linguagem clara
O Voxtral TTS é um modelo autoregressivo com backbone transformer, complementado por um bloco de fluxo acústico e um codec neural. Em números, o backbone possui aproximadamente 3,4 bilhões de parâmetros, o transformador acústico de flow matching adiciona cerca de 390 milhões e o codec neural, mais 300 milhões, totalizando a casa de 4 bilhões de parâmetros. Esse arranjo separa a compreensão semântica da fala dos detalhes acústicos, permitindo naturalidade sem sacrificar velocidade de geração.
Para agentes de voz, latência é tudo. A Mistral informa latência de modelo de 70 milissegundos em um cenário típico, com fator de tempo real aproximado de 9,7 vezes mais rápido que o tempo de reprodução. O sistema é capaz de gerar até 2 minutos de áudio nativamente, e a API faz o gerenciamento inteligente de streams longos. Em termos práticos, dá para começar a falar antes que o usuário perca o ritmo da conversa, um ponto crítico para retenção em contact centers e assistentes embutidos em apps móveis.
Vale situar no panorama técnico. Pesquisas recentes como VoXtream2 vêm explorando TTS full stream com primeiro pacote de áudio em poucas dezenas de milissegundos, controle dinâmico de fala e execução mais rápida que tempo real em GPUs de consumo. O Voxtral TTS aparece alinhado com essa fronteira, entregando início de áudio rápido e controle de emoção, atributos que otimizam a experiência conversacional.
Idiomas, vozes e adaptação para marca
A versão inicial do Voxtral TTS suporta 9 idiomas, inglês, francês, alemão, espanhol, holandês, português, italiano, hindi e árabe. O modelo foi treinado para se adaptar a uma voz personalizada com referência de apenas 3 segundos e para capturar nuances de sotaque, pausas e entonação, inclusive com adaptação cruzada de idioma, por exemplo, gerar inglês com timbre e sotaque de uma voz de referência francesa. Para empresas, isso significa levar identidade vocal de marca a múltiplos mercados sem reconstruir vozes do zero.
A Mistral disponibiliza vozes pré definidas na API, porém o objetivo é que equipes conectem bibliotecas internas e variem a emoção, do neutro ao entusiasmado, do casual ao formal. Em uma esteira bem orquestrada, times de CX e compliance conseguem criar guidelines para emoção e velocidade de fala por tipo de atendimento, ajustando a experiência sem mexer na base técnica.
![Comparativo de preferência humana do Voxtral TTS]
Integrações, APIs e fluxo speech-to-speech
O Voxtral TTS chega integrado ao ecossistema Mistral. O texto destaca testes rápidos no Mistral Studio, uso no Le Chat e documentação para produção. Em pipelines empresariais, a peça que completa o ciclo é combinar Voxtral Transcribe para reconhecimento de fala, LLM para raciocínio e Voxtral TTS para resposta falada. A Mistral posiciona explicitamente o TTS para operar lado a lado com o Transcribe, cobrindo cenários como suporte ao cliente, serviços financeiros, manufatura, setor público e tradução em tempo real.
O preço claro por 1 mil caracteres reduz a fricção de testes de negócio, desde POCs até rollouts com volume. Em organizações reguladas, a disponibilidade de pesos abertos para pesquisa, ainda que com licença não comercial, facilita auditoria técnica, avaliação de risco e comparação com alternativas proprietárias, uma preocupação levantada de forma recorrente por analistas ao falar de voz no ambiente corporativo.

![Diagrama da arquitetura Voxtral TTS]
Como projetar agentes de voz com Voxtral TTS
- Desenho do turn taking. Ajustar a política de barge in, de forma que o agente comece a falar assim que tiver confiança suficiente no próximo trecho. O fator de tempo real e o início de fala em dezenas de milissegundos permitem streams incrementais.
- Emoção e persona. Usar presets como ponto de partida e depois calibrar emoção por tipo de tarefa, confirmação de dados mais neutra, resolução bem sucedida mais calorosa, cobranças com formalidade. O suporte a sotaques e adaptação com poucos segundos de referência acelera a criação de vozes de marca.
- Métricas certas. Além de ASR e TTS, medir interrupções, sobreposições, tempo de resposta percebido e satisfação do usuário. A Mistral chama atenção para avaliações humanas, que capturam naturalidade e nuances culturais melhor do que métricas automáticas isoladas.
- Custos previsíveis. Mapear custo por contato com base no preço por 1 mil caracteres e nos comprimentos médios de resposta. Pequenas otimizações de prompt e resumo podem reduzir significativamente o consumo.
Comparativos e contexto competitivo
O lançamento do Voxtral TTS acontece em paralelo à evolução de modelos de transcrição da mesma família, que focam sub 200 milissegundos no modo em tempo real. Essa pressão por latência vem sendo tema em reportagens e análises setoriais, porque relacionamento e empatia caem quando a resposta demora segundos. O esforço da Mistral de reduzir o tempo até o primeiro áudio e manter naturalidade ataca exatamente essa dor.
Ao avaliar mercado, vale cruzar três eixos, qualidade percebida por humanos, latência ponta a ponta e portabilidade. Enquanto alguns TTS proprietários brilham em naturalidade e variedade de vozes, nem sempre viabilizam deploy local ou inspeção do pipeline. No outro extremo, linhas de pesquisa como VoXtream2 mostram que é possível falar quase imediatamente, mantendo controle de velocidade. O Voxtral TTS se posiciona no meio certo, aberto o suficiente para pesquisa, pronto para produção via API e com números de latência que habilitam conversas fluidas.
Casos práticos para começar já
- Contact center e help desk. A voz precisa soar humana, rápida e consistente com a marca, especialmente em picos. Voxtral TTS, com adaptação por poucos segundos e preço por caracteres, permite orquestrar tons diferentes por tipo de fila.
- Voice bots em apps e web. Em cadastros e pagamentos, a latência de início é crítica para o usuário não travar. O fator de tempo real indicado atende bem a UX de instruções curtas e confirmações.
- Assistentes embarcados. Em automotivo e dispositivos em campo, previsibilidade e controle importam. Ter pesos abertos para pesquisa facilita POCs locais e discussões de segurança com engenharia de plataforma.
- Tradução simultânea. A capacidade de adaptação cruzada de idioma e sotaque habilita roteiros de speech-to-speech com identidade vocal consistente, algo valioso em treinamentos e suporte multilíngue.
Perguntas frequentes que times técnicos fazem
- Como garantir que o agente não pareça robótico quando responde rápido. Combinar ajuste de emoção e cadência com políticas de interrupção cuidadosas. Latência baixa ajuda, mas naturalidade vem de emoção bem dosada e prosódia que respeita contexto.
- Qual o impacto do tamanho do modelo. Com cerca de 4B de parâmetros divididos entre linguagem, acústica e codec, o Voxtral TTS foca eficiência sem abrir mão de naturalidade. Esse balanço é o que viabiliza iniciar áudio rápido e manter timbre estável em frases longas.
- Como medir qualidade sem viés. Usar testes A B com ouvintes nativos por mercado, comparando naturalidade e sotaque ao lado de métricas automáticas, seguindo a diretriz que a Mistral enfatizou nas avaliações humanas.
Reflexões e insights ao longo do caminho
Agentes de voz úteis nascem quando três camadas se alinham, compreensão, decisão e fala. A camada de fala sempre foi a mais sensível, porque pequenas pausas mudam a experiência. Quando um TTS inicia áudio em dezenas de milissegundos e mantém emoção controlável, o diálogo flui. É disso que empresas precisam em canais de atendimento e vendas, respostas que não quebram o clima.
Outro ponto é estratégia de plataforma. Pesos abertos para pesquisa, ainda que não comerciais, não são só gesto para a comunidade. Formam a base para auditoria, comparações justas e aprendizado coletivo mais rápido. A prática tende a reduzir o ciclo de confiança entre times de segurança, jurídico e engenharia quando chega a hora de liberar o primeiro piloto em produção.
Conclusão
Voxtral TTS traz uma combinação rara de baixa latência, naturalidade e adaptabilidade, com 4B de parâmetros, suporte a 9 idiomas e um preço objetivo por 1 mil caracteres. Em conjunto com Voxtral Transcribe, fecha o ciclo de voz para agentes conversacionais que precisam operar em ambientes exigentes, de contact centers a apps com milhões de usuários.
O cenário de TTS avança rápido, mas alguns critérios permanecem estáveis, começar a falar em milissegundos, soar humano em múltiplas culturas e caber no orçamento. O Voxtral TTS sinaliza que esse trio já é possível em produção. O próximo passo está nas mãos de quem desenha experiências, alinhar emoção, persona e métricas de negócio para fazer da voz um ativo competitivo real.