Tinker lança disponibilidade geral, apresenta Kimi K2 Thinking e suporte a visão
A Thinking Machines libera o Tinker para todos, adiciona o modelo de raciocínio Kimi K2 Thinking e traz entrada de imagens com Qwen3-VL, abrindo caminho para treinos e inferência multimodal em escala.
Danilo Gato
Autor
Introdução
Tinker disponibilidade geral deixou de ser promessa. A Thinking Machines abriu a plataforma, removeu a lista de espera e estreou três novidades de peso, Kimi K2 Thinking no catálogo de modelos, amostragem compatível com a API da OpenAI e suporte a entrada de visão com Qwen3‑VL. O anúncio oficial foi publicado em 12 de dezembro de 2025 e marca uma virada para quem quer treinar, ajustar e servir modelos com menos fricção operacional.
Kimi K2 Thinking chega como o novo motor de raciocínio no Tinker. Trata‑se de um Mixture‑of‑Experts de escala trilionária, projetado para cadeias longas de pensamento e uso intenso de ferramentas, com janela de contexto que atinge 256 mil tokens e suporte robusto a orquestrações de agentes. Essas características, detalhadas pela Together AI e por reportagens técnicas, colocam o K2 como opção competitiva para tarefas que exigem planejamento multi‑etapas, busca e código.
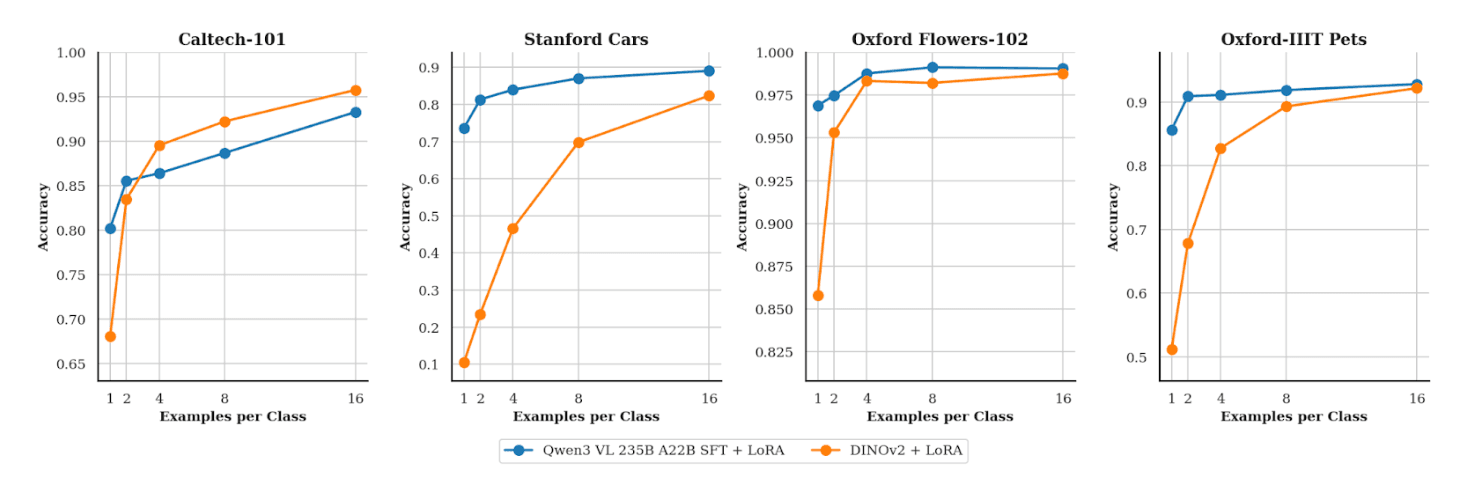
Além disso, o Tinker agora aceita entrada de imagens com Qwen3‑VL nas variantes 30B e 235B, o que habilita pipelines multimodais para classificação, VQA, leitura de documentos e automação de interfaces. A equipe mostrou exemplos práticos e comparou o fine‑tuning de um VLM com um baseline vision only como DINOv2, com ganhos claros em cenários de poucos exemplos.
O que este artigo aborda
- Por que a disponibilidade geral do Tinker muda o jogo para times pequenos e grandes
- O que diferencia o Kimi K2 Thinking em arquitetura, benchmarks e uso prático
- Como a compatibilidade com a API da OpenAI reduz tempo de integração
- O que o suporte a visão com Qwen3‑VL viabiliza em produtos reais
- Passos táticos para experimentar sem estourar o orçamento
Kimi K2 Thinking, o que muda no raciocínio de agentes
A chegada do Kimi K2 Thinking ao Tinker adiciona um modelo pensado para raciocínio profundo e uso de ferramentas em sequência. A arquitetura é um Mixture‑of‑Experts com cerca de 1 trilhão de parâmetros totais, 32 bilhões ativos por passo, 61 camadas e mecanismo de Multi‑head Latent Attention. O modelo opera com quantização nativa INT4 aplicada via QAT e janela de 256K tokens, um conjunto de escolhas que combina escala, custo e desempenho para cadeias longas de pensamento.
Do ponto de vista de uso, o K2 Thinking foi treinado para intercalar raciocínio de cadeia de pensamento com chamadas de função, chegando a executar 200 a 300 tool calls sequenciais sem intervenção humana segundo divulgações recentes da comunidade e de veículos que acompanharam o lançamento. Em avaliações públicas citadas pela imprensa especializada, o K2 Thinking apresentou resultados de ponta em suites como Humanity’s Last Exam e BrowseComp, além de bons números em benchmarks de código como SWE‑Bench Verified e LiveCodeBench v6.
No Tinker, o K2 Thinking entra como modelo de raciocínio para cenários que exigem análise longa, pesquisa com navegação e composição de passos. Para produtos, isso significa atender tarefas como investigação automatizada com fontes abertas, depuração de bases de código extensas e planejamento de fluxos de trabalho. Para pesquisa, significa iterar soluções de agentes com menos dor operacional, já que a plataforma abstrai o mapeamento do seu loop de treino para um cluster de GPUs.
Compatibilidade com a API da OpenAI, integração em minutos
O Tinker já expunha primitives próprias, como forward_backward, optim_step e sample, mas agora oferece um caminho alternativo compatível com a API da OpenAI para amostragem de checkpoints, inclusive durante o treino. Na prática, basta referenciar um checkpoint com um URI do tipo tinker://… e chamar a interface de completions. Isso simplifica plug and play com ferramentas, SDKs e gateways que esperam a semântica da OpenAI.
Exemplo de chamada apresentado pela equipe do Tinker:
response = openai_client.completions.create(
model="tinker://0034d8c9-0a88-52a9-b2b7-bce7cb1e6fef:train:0/sampler_weights/000080",
prompt="The capital of France is",
max_tokens=20,
temperature=0.0,
stop=["\n"],
)
Essa camada de compatibilidade encurta o tempo de integração com frameworks de inferência e gateways que suportam roteamento e observabilidade, como o Vercel AI Gateway, que recentemente adicionou suporte direto aos modelos Kimi K2 Thinking. Em ambientes corporativos, essa convergência de APIs reduz retrabalho e acelera pilotos.
Visão no Tinker com Qwen3‑VL, um passo prático para multimodal
O Tinker incorporou dois modelos de visão e linguagem, Qwen3‑VL‑30B‑A3B‑Instruct e Qwen3‑VL‑235B‑A22B‑Instruct. A entrada de imagens é feita intercalando um ImageChunk em bytes com um texto, o que torna a representação uniforme para SFT e RL. O post oficial traz o exemplo mínimo e aponta uma receita de cookbook para treinar classificadores de imagens.
![Gráfico de comparação de acurácia Qwen3-VL vs DINOv2]
Nos experimentos divulgados, o time fine‑tunou o Qwen3‑VL‑235B‑A22B‑Instruct como classificador em quatro datasets clássicos, Caltech 101, Stanford Cars, Oxford Flowers e Oxford Pets, e comparou com um baseline DINOv2‑base. No regime de dados limitados, o VLM superou o baseline, algo coerente com a hipótese de que VLMs trazem conhecimento semântico de linguagem que ajuda a generalizar com menos exemplos por classe. Para times sem grandes orçamentos de rotulagem, isso é uma avenida interessante para alcançar resultados úteis mais cedo.
Na prática do produto, Qwen3‑VL abre espaço para múltiplos casos, análise de documentos com OCR robusto, QA visual sobre relatórios e planilhas, leitura de telas e automação de GUI, inspeção de peças em linhas de produção, extração de dados de notas fiscais e atendimento ao cliente que entende fotos e capturas de tela. Plataformas independentes já listam a variante 235B com janelas de contexto acima de 250K tokens, preços competitivos e deploy via vLLM, o que facilita testes rápidos fora do Tinker quando necessário.
![Logo do Qwen, família Qwen3-VL]
Por que a disponibilidade geral do Tinker importa de verdade
Sair da lista de espera significa reduzir barreiras em três frentes. Primeiro, acesso imediato a uma prateleira que combina modelos de raciocínio e instrução, incluindo Kimi K2 Thinking, Qwen3 e Llama, com experimentação acelerada por LoRA. Segundo, unificação de treino, fine‑tuning e inferência compatível com OpenAI API, que conversa com SDKs e painéis existentes. Terceiro, suporte nativo a visão, que permite ir além do texto sem reescrever o pipeline. O anúncio oficial lista esses pilares de forma direta, e veículos independentes reforçam como o Tinker mapeia loops de treino em clusters e abstrai falhas e agendamento de GPU.

Para times de produto, isso se traduz em menor tempo do primeiro experimento ao piloto útil. Para pesquisa aplicada, significa gastar energia na lógica de treino e nos dados, e não em scripts de orquestração. Para lideranças, significa um caminho de avaliação contínua por custos previsíveis, já que LoRA reduz memória e acelera ciclos de teste.
Benchmarks e o papel do K2 no ecossistema
Benchmarks não contam toda a história, mas ajudam a balizar expectativas. Reportagens recentes reuniram números divulgados pela Moonshot indicando que o K2 Thinking alcançou 44,9 por cento no Humanity’s Last Exam, 60,2 por cento no BrowseComp, 71,3 por cento no SWE‑Bench Verified e 83,1 por cento no LiveCodeBench v6. Também há menções a 56,3 por cento no Seal‑0 e a um contexto de 256K com execução de 200 a 300 tool calls. Esses dados posicionam o K2 no topo entre modelos de pesos abertos, disputando espaço com alternativas como MiniMax‑M2 e desafiando modelos proprietários recentes.
Vale reforçar a origem e o momento. Em julho de 2025, a Reuters destacou que a Moonshot abriu o Kimi K2 para recuperar tração no mercado chinês, com foco em capacidades de agente e código. Desde então, provedores e gateways passaram a listar K2 Thinking como opção pronta para uso, e o Tinker agora o traz para o ambiente de treino e fine‑tuning. O encadeamento desses fatos explica por que a incorporação no Tinker é relevante para adoção global.
Como testar o Tinker com baixo atrito
- Comece pequeno com LoRA. A própria documentação e artigos de terceiros lembram que o Tinker foca em adapters de baixo custo, ideais para explorar várias hipóteses em paralelo. Use conjuntos de validação apertados para medir ganhos por classe de dado.
- Aproveite a compatibilidade OpenAI para plugar no que a equipe já domina. Se hoje o time usa SDKs com base_url, bastam poucas linhas para atingir um checkpoint do Tinker. Isso reduz a curva de adoção e mantém telemetria padronizada.
- Avalie K2 Thinking quando a tarefa exige raciocínio longo e ferramenta, por exemplo orquestração de navegação, geração com pesquisa e automação de código. Benchmarks recentes e especificações técnicas sugerem que o K2 foi treinado para esse perfil.
- Explore visão com Qwen3‑VL para acelerar provas de conceito em OCR de documentos, VQA e classificação few‑shot. Os resultados do cookbook comparam bem com um baseline DINOv2 no regime de poucos exemplos.
Custos, performance e trade‑offs
A escolha entre um VLM e um backbone exclusivamente de visão tem implicações de custo por passo e latência. Qwen3‑VL‑235B é massivo, porém plataformas de terceiros relatam janelas de contexto amplas e custos por milhão de tokens que podem ser competitivos quando comparados com modelos fechados de raciocínio multimodal. O efeito prático é que, para tarefas com pouco dado rotulado, o ganho de data efficiency pode compensar o custo unitário de tokens. Faça experimentos com cortes por orçamento, avaliando custo por objetivo de negócio, como redução de TAT ou aumento de precisão.
No lado do K2 Thinking, o uso de QAT com INT4 para componentes MoE, combinado à ativação esparsa de especialistas, favorece throughput em raciocínio pesado e janelas longas. Para quem precisa de autonomia de agentes por muitas etapas, essa combinação é um diferencial. Ainda assim, medições locais podem variar por engine e hardware. Ajuste batch size, controle de pensamentos e profundidade de raciocínio em função da latência desejada.
Exemplo rápido de pipeline multimodal no Tinker
A API de visão utiliza a mesma representação do texto, o que simplifica o treino supervisionado e o RL. O exemplo mínimo mostrado pelo time ilustra a interlevação de chunks de imagem e texto. Partindo disso, dá para construir um classificador few‑shot com prompts de sistema claros e rótulos controlados.
model_input = tinker.ModelInput(chunks=[
tinker.types.ImageChunk(data=image_data, format="png"),
tinker.types.EncodedTextChunk(tokens=tokenizer.encode("What is this?")),
])
Combine com LoRA para adaptar rapidamente a classes internas, por exemplo, tipos de documentos ou categorias de defeitos visuais. Avalie acurácia por classe e a qualidade da explicação textual gerada pelo VLM.
Caminho de adoção recomendado
- Semana 1, criar conta no Tinker, rodar exemplos do cookbook e validar amostragem compatível com OpenAI em um checkpoint público. Objetivo, telemetria e latência base.
- Semanas 2 a 3, validar Kimi K2 Thinking em tarefas de raciocínio que exigem ferramenta e múltiplos passos, como pesquisa com navegação e refatoração assistida de código em repositórios extensos. Registre custo por tarefa e estabilidade ao longo de sessões longas.
- Semana 4, acoplar visão com Qwen3‑VL para um caso prático simples, por exemplo, classificar documentos ou extrair campos de faturas com poucos exemplos rotulados. Compare contra um baseline de visão pura para medir ganho de data efficiency.
Perguntas frequentes que têm aparecido
- O K2 Thinking funciona em provedores e gateways de terceiros. Sim, há listagens recentes em gateways como o da Vercel e em catálogos que consolidam múltiplos modelos. Isso ajuda a testar fora do Tinker quando a governança pede isolamento entre treino e produção.
- Qwen3‑VL‑235B é difícil de rodar on‑prem. O tamanho exige GPUs potentes, porém provedores de inferência gerenciada e engines como vLLM vêm simplificando o deploy. Avalie custo contra volume, muitas vezes faz sentido usar endpoints gerenciados.
- Como ficam preços e limites do K2 Thinking em provedores externos. Diferem por plataforma, com reduções anunciadas a partir de novembro de 2025 no ecossistema Moonshot. Verifique condições atuais ao integrar.
Reflexões e insights
Disponibilidade geral do Tinker cria uma ponte prática entre pesquisa de ponta e entrega de produto. Kimi K2 Thinking atende a lacuna de raciocínio profundo com custo equilibrado por meio de MoE esparso e quantização consciente, enquanto a compatibilidade com API da OpenAI remove a barreira clássica de integração. O suporte a visão amplia o leque para além do texto, algo indispensável em fluxos que já nascem multimodais, como atendimento com imagens, inspeção e leitura de telas.
O recado para 2026 é simples. Padrões de API convergindo, modelos de raciocínio cada vez mais competentes em planejar e agir, e VLMs se mostrando eficientes em dados limitados. Com Tinker aberto, o ciclo de experimentar, medir e iterar ganhou velocidade. Isso não elimina o trabalho duro nos dados e na avaliação, mas coloca a tecnologia ao alcance de times menores e acelera a curva para quem já estava no jogo.
Conclusão
A abertura do Tinker, somada ao Kimi K2 Thinking e ao suporte a Qwen3‑VL, forma um pacote coerente, acesso amplo, raciocínio profundo e visão. A compatibilidade com a API da OpenAI fecha a conta ao permitir integrações rápidas com toolings existentes. Para quem precisa de agentes que pensam por muitas etapas e de pipelines multimodais, o caminho para sair do laboratório e ir ao produto ficou mais curto.
Os próximos meses devem consolidar padrões e reduzir ainda mais atritos de custo. O momento ideal para testar é agora, enquanto as curvas de aprendizado e de preço ainda jogam a favor de quem experimenta primeiro, mede com rigor e transforma resultados em vantagens reais de negócio.